

Was ist ungeordnetes Greifen in der 3D-Vision?
Im Bereich der Robotik und Computer Vision, unordered grasping bezieht sich auf die Fähigkeit eines Robotersystems, Gegenstände aus unstrukturierten, verstreuten Umgebungen zu erkennen und zu greifen, ohne vorheriges Wissen über ihre Anordnung oder Position. Im Gegensatz zu "geordnetem Greifen", bei dem Gegenstände ordentlich ausgerichtet oder in vorhersehbaren Orientierungen präsentiert werden (z. B. auf einem Förderband), behandelt ungeordnetes Greifen das Chaos realer Szenarien – wie Haufen von Gegenständen in einem Behälter, verstreute Artikel auf einem Tisch oder willkürlich gestapelte Produkte in einem Lagerhaus. Diese Technologie ist entscheidend für Anwendungen wie automatisiertes Behältergreifen, Logistiksortierung und adaptive robotergesteuerte Manipulation. Da Industrien mehr Automatisierung anstreben und Roboter jenseits kontrollierter Umgebungen eingesetzt werden, hat sich ungeordnetes Greifen als Eckpfeiler für wirklich autonome robotergesteuerte Operationen etabliert.
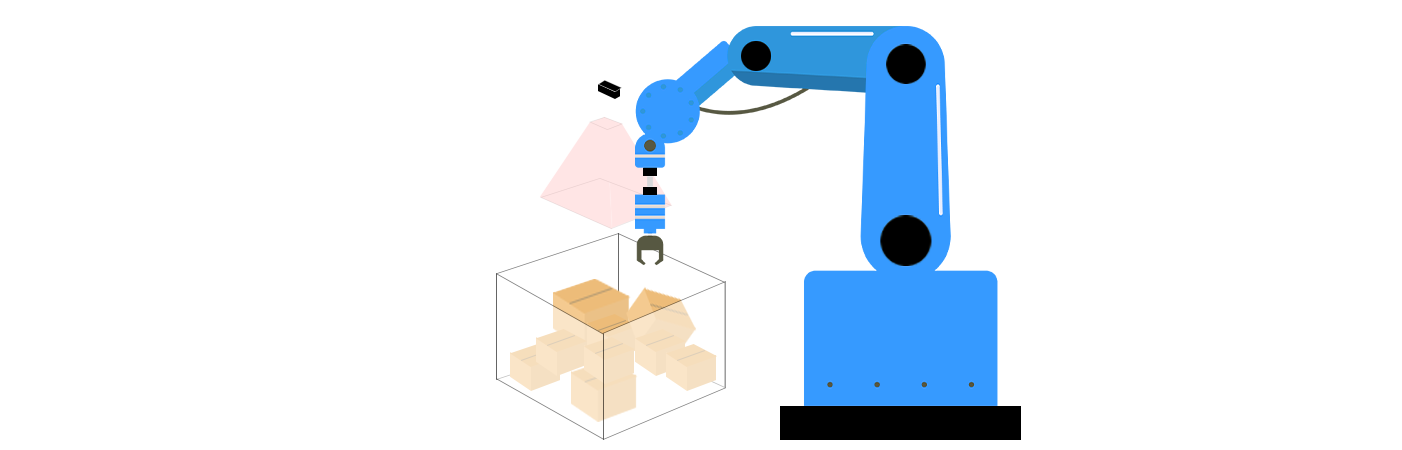
Kernkomponenten des ungeordneten Greifens in der 3D-Vision
Ungeordnetes Greifen kombiniert 3D-Visionstechnologien und robotikalgorithmen um drei Schlüsselausforderungen zu lösen: Wahrnehmung, Greifplanung und Ausführung. Diese Komponenten arbeiten zusammen, um Robotern zu ermöglichen, ihre Umgebung zu verstehen, die beste Weise zu bestimmen, wie sie mit Objekten interagieren sollen, und Aktionen präzise auszuführen.
1. 3D-Wahrnehmung und Szenenverstehen
Tiefenschätzung : 3D-Visionssysteme verwenden Sensoren wie LiDAR, Strukturlichtkameras oder Stereokameras, um Tiefeninformationen aufzunehmen und Punktwolken oder 3D-Modelle der unordentlichen Szene zu erstellen. LiDAR sendet zum Beispiel Laserstrahlen aus, die an Objekten reflektiert werden und zum Sensor zurückkehren, wobei Entfernungen auf Basis des Laufzeitprinzips berechnet werden. Strukturlichtkameras projizieren Muster auf Objekte und analysieren, wie diese Muster sich verformen, um Tiefeninformationen zu ableiten, während Stereokameras die menschliche Zwei-Augen-Wahrnehmung nachahmen, indem sie zwei Linse benutzen, um Entfernungen durch Triangulation zu bestimmen.
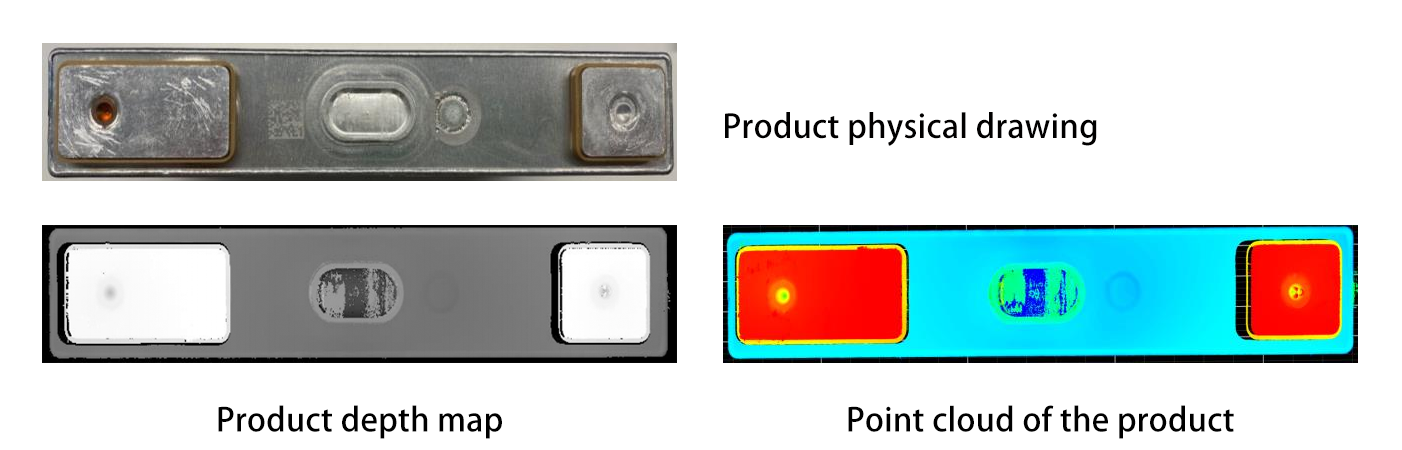
Objektsegmentierung und -erkennung : Fortgeschrittene Algorithmen (z. B. Deep-Learning-Modelle wie PointNet oder Mask R-CNN) verarbeiten 3D-Daten, um einzelne Objekte von der Unordnung zu trennen und sie zu identifizieren. PointNet, ein Pionier im Bereich des 3D-Deep Learnings, verarbeitet Punktwolken-Daten direkt, ohne sie in ein reguläres Gitter umzuwandeln, was es ermöglicht, die geometrischen Merkmale von Objekten in ihrem nativen Format zu verstehen. Mask R-CNN erweitert hingegen den beliebten Faster R-CNN-Rahmen, um Instanzsegmentierung in 3D durchzuführen, wodurch Roboter spezifische Objekte aus komplexen Szenarien unterscheiden und isolieren können. Zum Beispiel könnte ein Roboter einen Metallteil von einem Kunststoffkomponenten in einem unsortierten Behälter durch die Analyse ihrer geometrischen Merkmale oder Oberflächentexturen unterscheiden. Darüber hinaus können Techniken wie semantische Segmentierung verschiedene Teile eines Objekts kennzeichnen, was nützlich ist, um Bereiche für das Greifen zu identifizieren.
2. Griffplanung im 3D-Raum
Sobald die Objekte identifiziert wurden, muss der Roboter bestimmen, wo und wie er sie greifen soll:
Generierung von Griffkandidaten : Algorithmen generieren potenzielle Griffe basierend auf der Form, Größe und den physikalischen Eigenschaften eines Objekts. Geometrische Ansätze könnten die konvexe Hülle eines Objekts analysieren, um stabile Kontaktpunkte zu finden, während physikbasierte Simulationen vorhersagen können, wie ein Greifer mit dem Objekt interagiert, wenn es ergriffen wird. Bei einer zylindrischen Flasche könnte das System vorschlagen, ihren Mittelteil mit parallelen Kiefern zu greifen; bei einer flachen Platte könnte es einen Kanten-Griff vorschlagen. In jüngster Zeit wurden generative adversarische Netze (GANs) eingesetzt, um durch das Lernen aus großen Datensätzen erfolgreicher Griffe vielfältige und realistische Griffoptionen zu generieren.
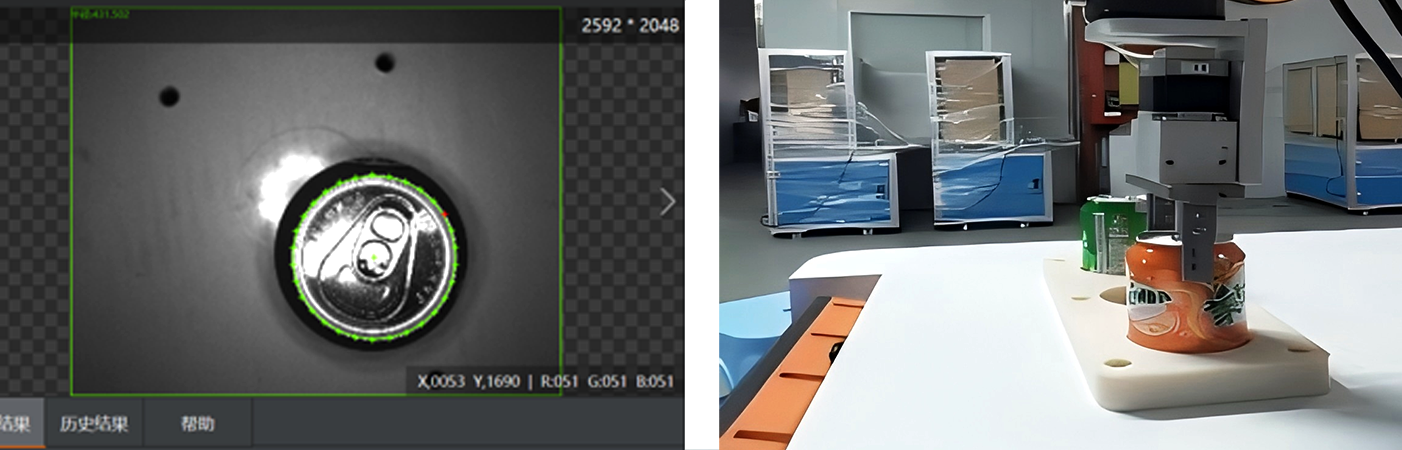
Griffqualitätsevaluierung : Jeder Kandidatengriff wird auf Stabilität (z. B., ob das Objekt rutschen wird), Machbarkeit (z. B., ob der Greifer des Roboters die Position einnehmen kann, ohne mit anderen Objekten zu kollidieren) und Sicherheit (z. B., Vermeidung von empfindlichen Bereichen) hin evaluiert. Maschinelles Lernen, trainiert anhand von Tausenden von 3D-Objektbeispielen, kann vorhersagen, welche Griffe am wahrscheinlichsten erfolgreich sind. Reinforcement Learning hat sich ebenfalls in diesem Bereich als sehr vielversprechend erwiesen, da Roboter durch Ausprobieren und Fehler in simulierten Umgebungen optimale Griffstrategien lernen können.
3. Roboter-Ausführung und Feedback
Der Roboter verwendet seinen Greifer oder Endeffektor, um den geplanten Griff auszuführen, dabei wird er durch eine genaue 3D-Pose-Schätzung geleitet, um sich mit der Position des Objekts auszurichten. Verschiedene Arten von Greifern, wie parallele Kieferngreifer, Saugnapf-Greifer oder mehrfingrige Hände, werden je nach den Eigenschaften des Objekts ausgewählt. Zum Beispiel sind Saugnapf-Greifer ideal für flache, nicht poröse Oberflächen, während mehrfingrige Hände unregelmäßig geformte Objekte mit größerer Geschicklichkeit behandeln können.
Echtzeit-Feedback : Sensoren (z. B. Kraft-Drehmoment-Sensoren oder Vision-Kameras) liefern während des Greifvorgangs sofortige Rückmeldung. Wenn das Objekt verrutscht oder der Greifer ausrutscht, kann der Roboter seinen Griff anpassen oder den Greifversuch wiederholen, was die Zuverlässigkeit in unordentlichen Umgebungen verbessert. Einige fortschrittliche Systeme verwenden sogar taktil eingebaute Sensoren im Greifer, um die Oberflächeneigenschaften und Härte des Objekts zu erfühlen, was flexiblere Greifstrategien ermöglicht. Wenn zum Beispiel der Sensor ein zartes Objekt erkennt, kann der Roboter die Greifkraft reduzieren, um Schäden zu vermeiden.
Herausforderungen beim ungeordneten Greifen
Ungeordnetes Greifen in der 3D-Vision steht vor erheblichen technischen Hürden:
Occlusion und Clutter : Wenn Objekte sich überlappen, ist es schwierig, sie zu segmentieren oder ihre volle Form wiederherzustellen. Zum Beispiel könnte ein Roboter Probleme haben, einen Löffel zu erkennen, der unter einem Haufen von Gabeln verborgen ist. Fortgeschrittene Techniken wie volumetrisches Rendering oder graphbasiertes Clustering helfen dabei, diese Ambiguitäten aufzulösen. Volumetrisches Rendering kann ein 3D-Modell der gesamten Szene erstellen, wodurch der Algorithmus die räumliche Ausdehnung der Objekte analysieren und versteckte Gegenstände identifizieren kann. Graphbasiertes Clustering behandelt jedes Objekt oder Punktwolke als Knoten in einem Graphen und nutzt die Beziehungen zwischen den Knoten, um überlappende Objekte zu trennen. Dennoch stellen hoch komplexe und dicht gepackte Clutter-Fälle weiterhin Herausforderungen dar.
Vielfältige Objekteigenschaften : Objekte mit komplexen Formen (z. B. hohle Behälter), flexiblen Materialien (z. B. Stoff) oder reflektierenden Oberflächen (z. B. Glas) sind schwer genau wahrzunehmen. Die Fusion mehrerer Sensoren (Kombination von RGB, Tiefen- und taktilen Daten) und Data Augmentation (Training von Modellen auf simulierten Variationen) lösen diese Probleme. Zum Beispiel kann die Kombination von Tiefendaten mit Infrarotsensoren helfen, das Verständnis der Form transparenter Objekte zu verbessern, während Data Augmentation maschinelles Lernen auf einer Vielzahl von Objekterscheinungen aussetzt, was ihre Generalisierungsfähigkeit verbessert.
Echtzeitleistung : Die Verarbeitung hochaufgelöster 3D-Daten und die schnelle Generierung von Greifplänen für eine robotergesteuerte Reaktion erfordert effiziente Algorithmen und Hardwarebeschleunigung (z. B. GPUs oder Edge-Computing-Einheiten). Dennoch ist es weiterhin eine große Herausforderung, Echtzeit-Leistung bei hoher Genauigkeit in komplexen Umgebungen zu erreichen, insbesondere beim Umgang mit großen Punktwolken oder hochaufgelösten 3D-Modellen.

Anwendungen und Zukunftsrichtungen
Industrieautomation : Ungeordnetes Greifen revolutioniert die Lagerlogistik. Zum Beispiel können Roboter mit 3D-Vision zufällige Gegenstände aus Containern für das Verpacken herausnehmen, was die Abhängigkeit von manuellem Sortieren reduziert. Unternehmen wie Amazon und Toyota haben solche Systeme bereits in ihre Lieferketten integriert. In der Automobilherstellung können Roboter mit Fähigkeiten zum ungeordneten Greifen Teile direkt aus Massenspeichern verarbeiten, was Produktionslinien optimiert und die Flexibilität erhöht.
Forschungsschwerpunkte :
Mehrfachgreifung : Entwicklung von Strategien, um mehrere Objekte gleichzeitig zu greifen oder Clutter neu zu positionieren, um auf verborgene Gegenstände zuzugreifen. Dies könnte erweiterte Bewegungsplanungsalgorithmen beinhalten, die die Wechselwirkungen zwischen mehreren Objekten während des Greifens und der Manipulation berücksichtigen.
Mensch-Roboter-Zusammenarbeit : Sicherstellen, dass Roboter sicher navigieren und Gegenstände in geteilten Räumen greifen können, sich an menschliche Bewegungen und unvorhersehbare Hindernisse anpassen. Dazu sind sophistizierte Wahrnehmungssysteme erforderlich, die zwischen Menschen und Objekten unterscheiden können, sowie Echtzeitalgorithmen für Bewegungsplanung, die auf Sicherheit setzen.
Fazit
Ungeordnetes Greifen in der 3D-Vision ist ein entscheidender Durchbruch für autonome Robotik, der Maschinen ermöglicht, mit der unstrukturierten Welt zu interagieren, wie es Menschen tun. Durch die Integration fortgeschrittener Wahrnehmung, intelligenter Planung und anpassungsfähiger Ausführung öffnet diese Technologie Branchen neue Effizienzmöglichkeiten und schafft den Weg zu vielseitigeren Servicerobotern. Da sich 3D-Sensoren weiter verbilligen und maschinelles Lernen robuster wird, wird ungeordnetes Greifen neue Automatisierungsmöglichkeiten erschließen und Roboter fähiger, zuverlässiger und besser auf die reale Welt vorbereitet machen. Die fortschreitende Forschung und Entwicklung in diesem Bereich versprechen, die Zukunft der Robotik von der industriellen Automatisierung bis hin zur täglichen Unterstützung zu verändern, indem sie Roboter befähigt, die Komplexitäten unstrukturierter Umgebungen mühelos zu meistern.





