

¿Qué es la Toma Desordenada en Visión 3D?
En el campo de la robótica y la visión por computadora, agarre desordenado se refiere a la capacidad de un sistema robótico para identificar y agarrar objetos desde entornos no estructurados y desordenados sin conocimiento previo de su disposición o postura. A diferencia del "agarrado ordenado", donde los objetos están alineados o presentados en orientaciones predecibles (por ejemplo, en una cinta transportadora), el agarrado desordenado aborda el caos de escenarios del mundo real, como montones de objetos en un contenedor, artículos esparcidos en un escritorio o productos apilados al azar en un almacén. Esta tecnología es vital para aplicaciones como la selección automática en contenedores, el clasificado en logística y la manipulación robótica adaptable. A medida que las industrias buscan una mayor automatización y los robots se mueven más allá de entornos controlados, el agarrado desordenado ha emergido como una piedra angular para alcanzar operaciones robóticas verdaderamente autónomas.
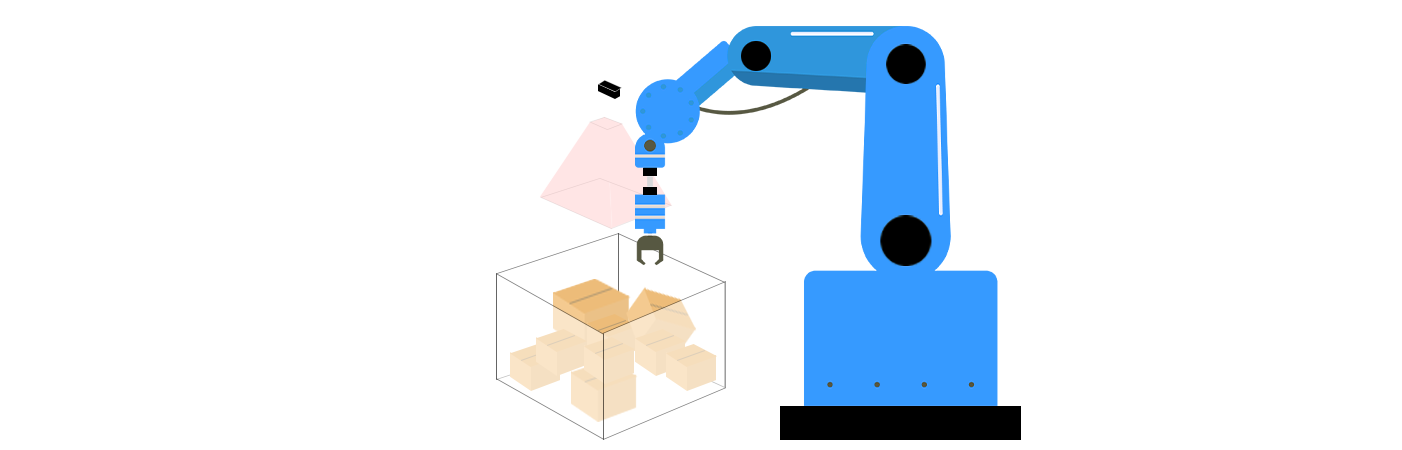
Componentes Principales del Agarrado Desordenado en Visión 3D
El agarrado desordenado combina tecnologías de visión 3D y algoritmos de robótica para resolver tres desafíos clave: percepción, planificación de agarre y ejecución. Estos componentes trabajan en conjunto para permitir que los robots comprendan su entorno, determinen la mejor manera de interactuar con los objetos y ejecuten acciones con precisión.
1. percepción 3D y Comprensión de la Escena
Sensado de Profundidad : Los sistemas de visión 3D utilizan sensores como LiDAR, cámaras de luz estructurada o cámaras estereoscópicas para capturar información de profundidad, creando nubes de puntos o modelos 3D de la escena desordenada. Por ejemplo, el LiDAR emite haces láser que rebotan en los objetos y regresan al sensor, calculando distancias basadas en el principio de tiempo de vuelo. Las cámaras de luz estructurada proyectan patrones sobre los objetos y analizan cómo se deforman estos patrones para inferir la profundidad, mientras que las cámaras estereoscópicas imitan la visión binocular humana utilizando dos lentes para triangular distancias.
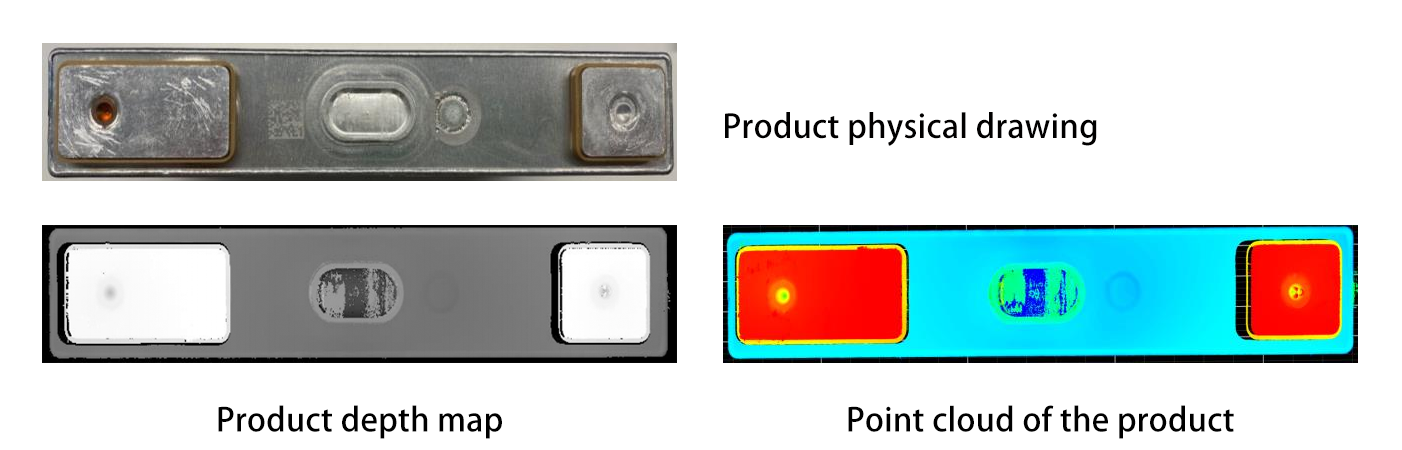
Segmentación y Reconocimiento de Objetos : Algoritmos avanzados (por ejemplo, modelos de aprendizaje profundo como PointNet o Mask R-CNN) procesan datos 3D para separar objetos individuales del desorden e identificarlos. PointNet, un pionero en el aprendizaje profundo 3D, procesa directamente los datos de la nube de puntos sin convertirlos en una cuadrícula regular, lo que le permite comprender las características geométricas de los objetos en su formato nativo. Mask R-CNN, por otro lado, extiende el marco popular Faster R-CNN para manejar la segmentación de instancias en 3D, permitiendo a los robots distinguir e aislar objetos específicos de escenas complejas. Por ejemplo, un robot podría distinguir una pieza metálica de un componente de plástico en un contenedor revuelto analizando sus características geométricas o texturas de superficie. Además, técnicas como la segmentación semántica pueden etiquetar diferentes partes de un objeto, lo cual es útil para identificar áreas adecuadas para agarrar.
2. Planificación de la Prenda en el Espacio 3D
Una vez identificados los objetos, el robot debe determinar dónde y cómo agarrarlos:
Generación de Candidatos para Agarre : Los algoritmos generan posibles poses de agarre basadas en la forma, tamaño y propiedades físicas de un objeto. Los enfoques geométricos podrían analizar la envolvente convexa de un objeto para encontrar puntos de contacto estables, mientras que las simulaciones basadas en física pueden predecir cómo un agarrador interactuará con el objeto durante el agarre. Para una botella cilíndrica, el sistema podría sugerir agarrar su mitad con mandíbulas paralelas; para una placa plana, podría proponer un agarre por pinza en el borde. Más recientemente, se han empleado redes generativas antagonistas (GANs) para generar candidatos a agarres diversos y realistas aprendiendo de grandes conjuntos de datos de agarrados exitosos.
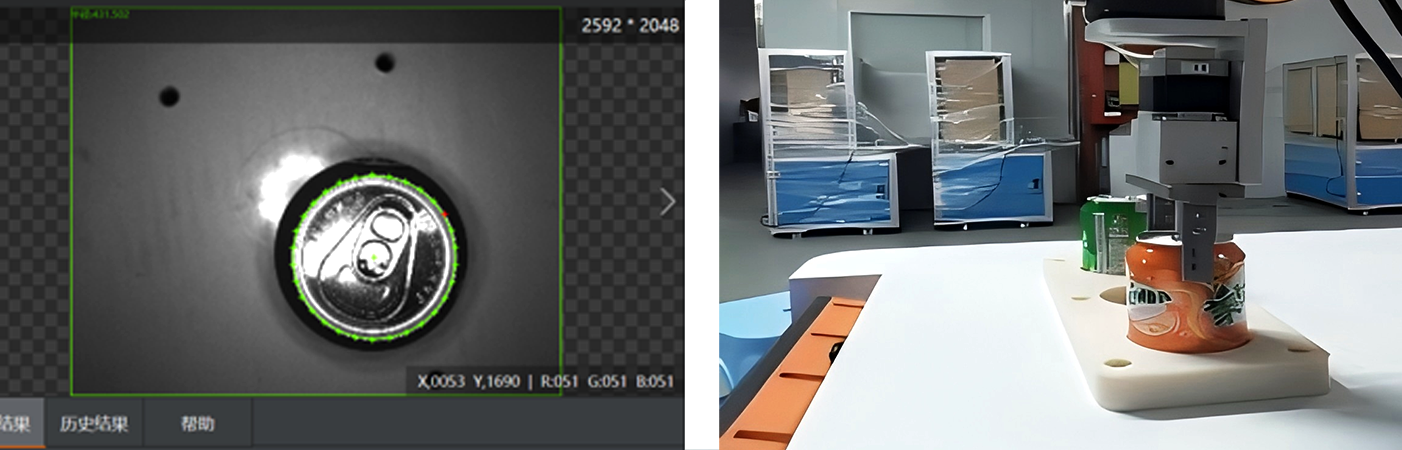
Evaluación de la Calidad del Agarre : Cada candidato a agarre se evalúa en términos de estabilidad (por ejemplo, si el objeto se deslizará), factibilidad (por ejemplo, si la pinza del robot puede alcanzar la postura sin chocar con otros objetos) y seguridad (por ejemplo, evitando áreas frágiles). Los modelos de aprendizaje automático, entrenados con miles de ejemplos de objetos en 3D, pueden predecir qué agarres tienen más probabilidades de tener éxito. El aprendizaje por refuerzo también ha mostrado un gran potencial en este campo, ya que los robots pueden aprender estrategias óptimas de agarre mediante ensayo y error en entornos simulados.
3. Ejecución Robótica y Retroalimentación
El robot utiliza su garra o efectuador final para ejecutar el agarre planificado, guiado por una estimación precisa de la postura 3D para alinearse con la ubicación del objeto. Diferentes tipos de garras, como garras de mandíbula paralela, copos de succión o manos multi-dedos, se seleccionan según las características del objeto. Por ejemplo, los copos de succión son ideales para superficies planas y no porosas, mientras que las manos multi-dedos pueden manejar objetos de forma irregular con mayor destreza.
Retroalimentación en Tiempo Real : Los sensores (por ejemplo, sensores de fuerza-torque o cámaras de visión) proporcionan retroalimentación instantánea durante el agarre. Si el objeto se desplaza o la garra resbala, el robot puede ajustar su agarre o volver a intentarlo, mejorando la fiabilidad en entornos desordenados. Algunos sistemas avanzados incluso utilizan sensores táctiles incrustados en la garra para detectar la textura y dureza del objeto, lo que permite estrategias de agarre más adaptativas. Por ejemplo, si el sensor detecta un objeto delicado, el robot puede reducir la fuerza de agarre para evitar daños.
Desafíos en el Agarre Desordenado
La captura desordenada en la visión 3D enfrenta importantes obstáculos técnicos:
Ocurrencia y Desorden : Cuando los objetos se superponen, es difícil segmentarlos o reconstruir su forma completa. Por ejemplo, un robot podría tener dificultades para distinguir una cuchara enterrada bajo un montón de tenedores. Técnicas avanzadas como el renderizado volumétrico o el agrupamiento basado en grafos ayudan a resolver estas ambigüedades. El renderizado volumétrico puede crear un modelo 3D de toda la escena, permitiendo que el algoritmo analice la ocupación espacial de los objetos e identifique elementos ocultos. El agrupamiento basado en grafos trata cada objeto o nube de puntos como un nodo en un grafo y utiliza las relaciones entre nodos para separar objetos superpuestos. Sin embargo, estos métodos aún enfrentan desafíos al lidiar con desorden altamente complejo y densamente empaquetado.
Propiedades diversas de objetos : Los objetos con formas complejas (por ejemplo, contenedores huecos), materiales flexibles (por ejemplo, tela) o superficies reflectantes (por ejemplo, vidrio) son difíciles de percibir con precisión. La fusión multisensor (combinando datos RGB, profundidad y táctiles) y el aumento de datos (entrenando modelos en variaciones simuladas) abordan estos problemas. Por ejemplo, combinar datos de profundidad con sensores infrarrojos puede ayudar a comprender mejor la forma de los objetos transparentes, mientras que el aumento de datos puede exponer a los modelos de aprendizaje automático a una amplia variedad de apariencias de objetos, mejorando su capacidad de generalización.
Rendimiento en tiempo real : Procesar datos 3D de alta resolución y generar planes de agarre lo suficientemente rápido para la respuesta robótica requiere algoritmos eficientes y aceleración por hardware (por ejemplo, GPUs o unidades de computación periférica). Sin embargo, lograr un rendimiento en tiempo real mientras se mantiene una alta precisión en entornos complejos sigue siendo un desafío significativo, especialmente cuando se trata con nubes de puntos grandes o modelos 3D de alta definición.

Aplicaciones y Tendencias Futuras
Automatización industrial : La toma desordenada está revolucionando la logística de almacenes. Por ejemplo, los robots equipados con visión 3D pueden seleccionar artículos aleatorios de contenedores para su embalaje, reduciendo la dependencia del clasificado manual. Empresas como Amazon y Toyota ya han integrado dichos sistemas en sus cadenas de suministro. En la fabricación automotriz, los robots con capacidades de toma desordenada pueden manejar piezas directamente desde el almacenamiento en masa, optimizando las líneas de producción e incrementando la flexibilidad.
Fronteras de Investigación :
Manejo Multi-Objeto : Desarrollar estrategias para agarrar múltiples objetos a la vez o reubicar el desorden para acceder a elementos ocultos. Esto podría implicar algoritmos avanzados de planificación de movimiento que consideren las interacciones entre varios objetos durante la toma y manipulación.
Colaboración Humano-Robot : Garantizar que los robots puedan navegar y manipular objetos de manera segura en espacios compartidos, adaptándose a los movimientos humanos y obstáculos impredecibles. Esto requiere sistemas de percepción sofisticados que puedan distinguir entre humanos y objetos, así como algoritmos de planificación de movimiento en tiempo real que prioricen la seguridad.
Conclusión
La manipulación desordenada en la visión 3D es un avance crítico para la robótica autónoma, permitiendo que las máquinas interactúen con el mundo desordenado y no estructurado de la misma manera que lo hacen los seres humanos. Al integrar una percepción avanzada, una planificación inteligente y una ejecución adaptable, esta tecnología impulsa la eficiencia en las industrias y abre las puertas a robots de servicio más versátiles. A medida que los sensores 3D se vuelven más baratos y los modelos de aprendizaje automático más robustos, la manipulación desordenada desbloqueará nuevas posibilidades en la automatización, haciendo que los robots sean más capaces, confiables y preparados para el mundo real. La investigación y desarrollo continuos en este campo prometen rediseñar el futuro de la robótica, desde la automatización industrial hasta la asistencia cotidiana, al empoderar a los robots para manejar las complejidades de entornos no estructurados con facilidad.





