

Deux types d'algorithmes pour la vision par ordinateur
La vision par ordinateur est devenue un pilier de l'automatisation industrielle, permettant un contrôle qualité efficace et la détection des défauts. Au cœur de la vision par ordinateur, des algorithmes sont utilisés pour reproduire le jugement visuel humain. Ces algorithmes peuvent être classés en deux grandes catégories : systèmes basés sur des règles et algorithmes d'apprentissage profond . Comprendre leurs principes, forces et limites est essentiel pour optimiser leurs applications dans des scénarios réels.
Systèmes basés sur des règles
Algorithmes à base de règles : Ces systèmes analysent des caractéristiques spécifiques d'un objet — telles que la couleur, la forme ou les valeurs en niveaux de gris — et les comparent à des seuils ou modèles établis. Par exemple :
- Une feuille de papier blanche avec des taches peut être marquée comme défectueuse car les taches présentent une valeur en niveaux de gris distincte du fond.
- Un produit ne comportant pas un logo standard (un modèle prédefini) est considéré comme (non conforme) par correspondance de modèle.

Avantages :
Facilité de déploiement les règles sont simples à programmer une fois que les motifs de caractéristiques sont bien définis.
Coût calculatoire faible : Exigences matérielles minimales en raison de calculs déterministes.
Limitations :
Exigences environnementales rigides : L'éclairage, les angles de caméra et le positionnement du produit doivent rester très cohérents.
Adaptabilité limitée : Même de légères variations dans l'apparence du produit (par exemple, fluctuations de la texture du matériau) ou des défauts irréguliers (par exemple, rayures aléatoires) peuvent entraîner des jugements erronés.
En pratique, les systèmes basés sur des règles se distinguent dans des environnements hautement contrôlés où les spécifications des produits et les conditions d'inspection sont strictement standardisées. Cependant, leur fragilité devient évidente dans des contextes dynamiques ou imprévisibles.
Algorithmes d'Apprentissage Profond : Apprendre à partir de la Complexité
L'apprentissage profond imite les processus cognitifs humains en formant des réseaux neuronaux sur de vastes ensembles de données. Contrairement aux systèmes basés sur des règles, ces algorithmes extraient automatiquement des caractéristiques des images, ce qui leur permet de gérer des scénarios complexes tels que :
Détection de défauts irréguliers (par exemple, fissures ou taches de formes aléatoires).
Différenciation des objets dans des arrière-plans encombrés.

Avantages :
Haute précision dans les environnements chaotiques : S'adapte aux variations d'éclairage, d'angles et d'incohérences de produit.
Généralisabilité : Une fois entraînés, les modèles peuvent reconnaître de nouveaux motifs de défauts au sein des catégories apprises.
Défis :
Faim de données : L'entraînement nécessite des centaines à des milliers d'images étiquetées, avec une forte dépendance aux échantillons défectueux. En fabrication, les défauts sont souvent rares, nécessitant des phases de collecte de données prolongées (de semaines à des mois).
Problèmes de scalabilité : Passer à une nouvelle spécification produit exige généralement un réentraînement à partir de zéro, augmentant les coûts en temps et en ressources.
Choisir le bon outil : le contexte compte
Le choix entre les algorithmes basés sur des règles et ceux d'apprentissage profond repose sur des cas d'utilisation spécifiques :
Systèmes basés sur des règles sont performants dans des productions en grand volume et standardisées (par exemple, composants de semi-conducteurs) où la cohérence est garantie.
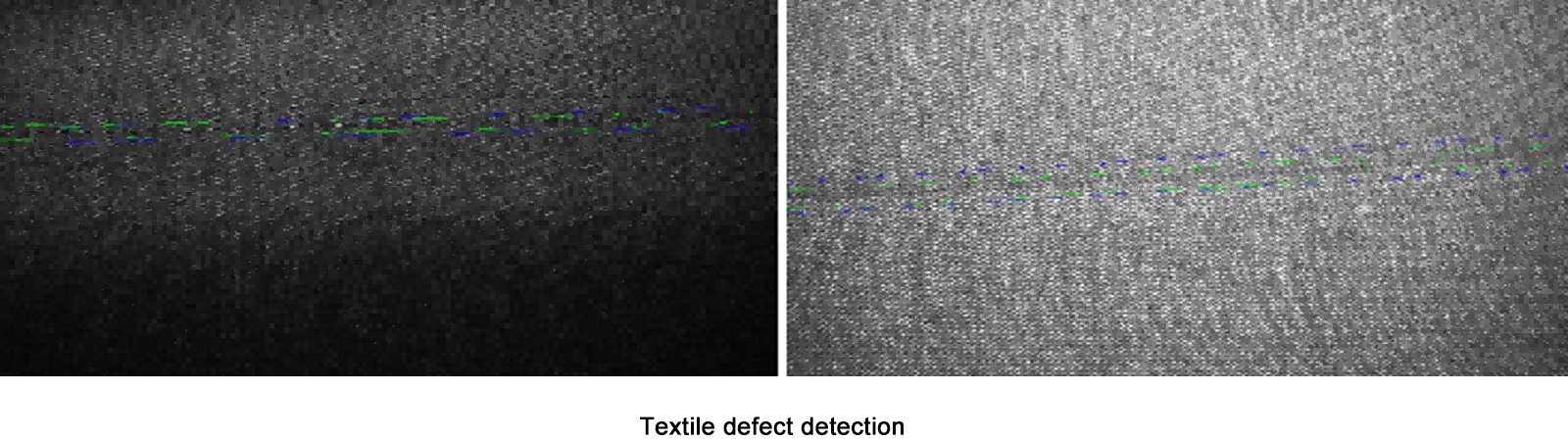
Apprentissage profond se distingue dans des scénarios à faible volume et forte variabilité (par exemple, détection de défauts dans les textiles) ou lorsque les défauts ne présentent pas de motifs prévisibles.
Notamment, des approches hybrides émergent. Par exemple, des filtres basés sur des règles peuvent prétraiter les images pour réduire les charges de travail en apprentissage profond, tandis que les outils de génération de données synthétiques atténuent les pénuries d'échantillons d'entraînement.
Conclusion
L'efficacité de la vision par machine dépend d'un alignement entre les capacités algorithmiques et les réalités opérationnelles. Les systèmes basés sur des règles offrent simplicité et rapidité, mais peinent dans des environnements imprévisibles. L'apprentissage profond offre flexibilité et précision, mais nécessite un investissement important au départ. En fin de compte, la stabilité de tout système repose sur trois facteurs : l'uniformité du produit, le contrôle de l'environnement et la diversité des échantillons. Maîtriser ces variables garantit que la vision par machine tient sa promesse de précision et de fiabilité.





