

Qu'est-ce que la prise non ordonnée en vision 3D ?
Dans le domaine de la robotique et de la vision par ordinateur, emprise non ordonnée réfère à la capacité d'un système robotique à identifier et saisir des objets dans des environnements non structurés et encombrés, sans connaissance préalable de leur disposition ou de leur orientation. Contrairement à la « prise ordonnée », où les objets sont alignés de manière nette ou présentés dans des orientations prévisibles (par exemple, sur une bande transporteuse), la prise non ordonnée gère le désordre des scénarios du monde réel - tels que des tas d'objets dans un conteneur, des éléments dispersés sur un bureau, ou des produits empilés aléatoirement dans un entrepôt. Cette technologie est essentielle pour des applications telles que le tri automatisé, le tri logistique et la manipulation robotique adaptative. Alors que les industries cherchent à augmenter l'automatisation et que les robots dépassent les environnements contrôlés, la prise non ordonnée est apparue comme un pilier pour atteindre des opérations robotiques véritablement autonomes.
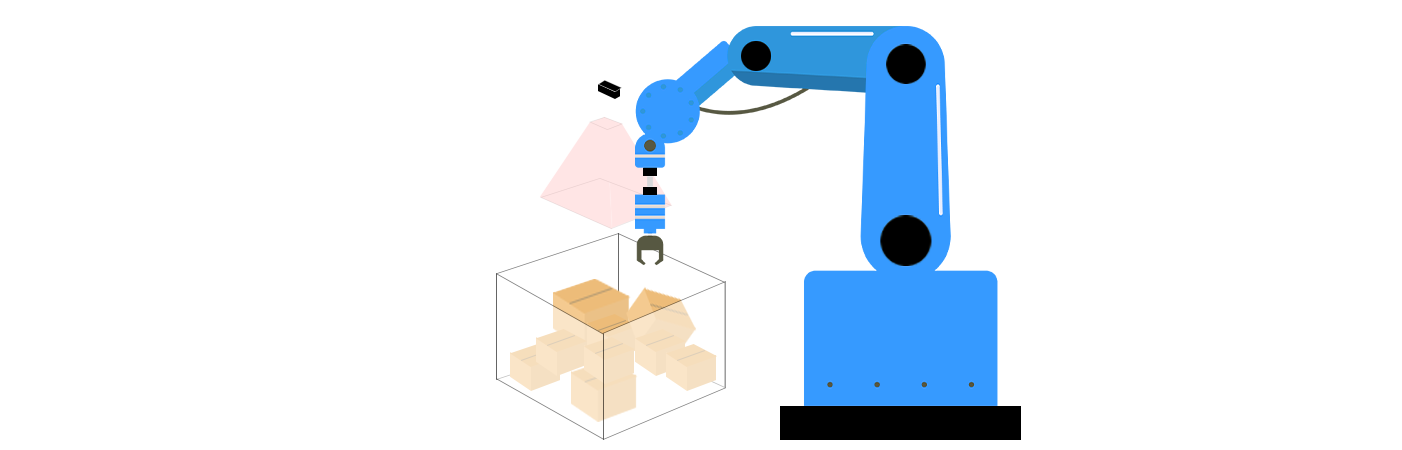
Composants principaux de la prise non ordonnée en vision 3D
La prise non ordonnée combine technologies de vision 3D et algorithmes robotiques résoudre trois défis clés : la perception, la planification de saisie et l'exécution. Ces composants travaillent en tandem pour permettre aux robots de comprendre leur environnement, de déterminer la meilleure façon d'interagir avec les objets et d'exécuter des actions avec précision.
1. perception 3D et Compréhension de la Scène
Mesure de Profondeur : Les systèmes de vision 3D utilisent des capteurs tels que le LiDAR, des caméras à lumière structurée ou des caméras stéréoscopiques pour capturer des informations de profondeur, créant des nuages de points ou des modèles 3D de la scène encombrée. Par exemple, le LiDAR émet des faisceaux laser qui se réfléchissent sur les objets et reviennent au capteur, calculant les distances selon le principe du temps de vol. Les caméras à lumière structurée projettent des motifs sur les objets et analysent comment ces motifs se déforment pour inférer la profondeur, tandis que les caméras stéréoscopiques imitent la vision binoculaire humaine en utilisant deux objectifs pour trianguler les distances.
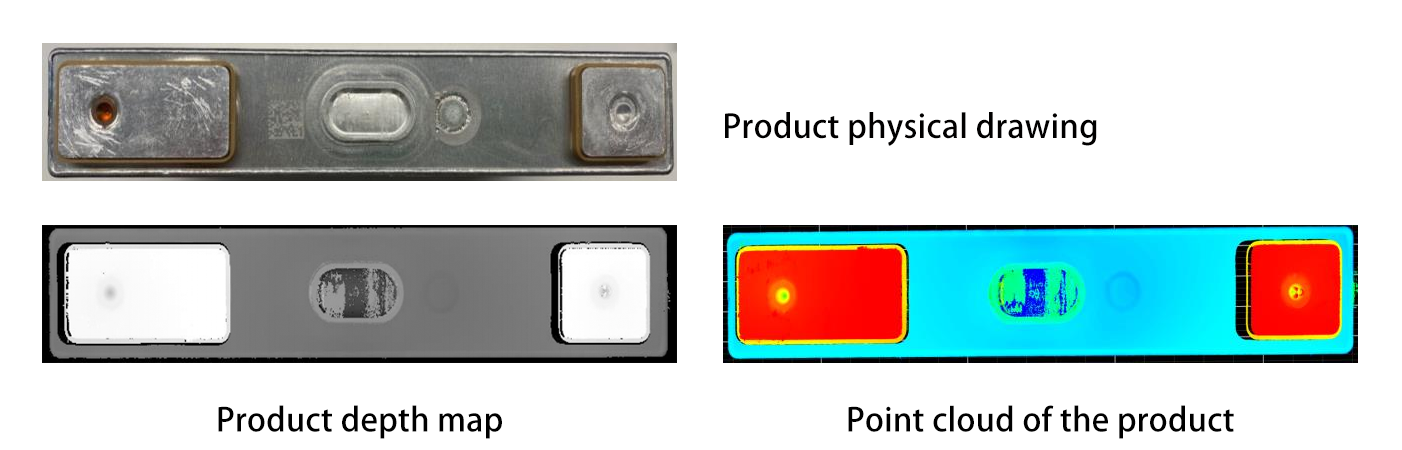
Segmentation et Reconnaissance d'Objets : Des algorithmes avancés (par exemple, des modèles d'apprentissage profond comme PointNet ou Mask R-CNN) traitent les données 3D pour séparer les objets individuels du désordre et les identifier. PointNet, un pionnier de l'apprentissage profond en 3D, traite directement les données de nuages de points sans les convertir en une grille régulière, lui permettant de comprendre les caractéristiques géométriques des objets dans leur format natif. Mask R-CNN, quant à lui, étend le cadre populaire Faster R-CNN pour gérer la segmentation d'instances en 3D, permettant aux robots de distinguer et d'isoler des objets spécifiques dans des scènes complexes. Par exemple, un robot pourrait différencier une pièce en métal d'un composant en plastique dans un conteneur en désordre en analysant leurs caractéristiques géométriques ou leurs textures de surface. De plus, des techniques comme la segmentation sémantique peuvent étiqueter différentes parties d'un objet, ce qui est utile pour identifier les zones appropriées pour la saisie.
2. Planification de la saisie dans l'espace 3D
Une fois les objets identifiés, le robot doit déterminer où et comment les saisir :
Génération de candidats pour la saisie : Des algorithmes génèrent des poses de préhension potentielles en fonction de la forme, de la taille et des propriétés physiques d'un objet. Les approches géométriques peuvent analyser l'enveloppe convexe d'un objet pour trouver des points de contact stables, tandis que les simulations basées sur la physique peuvent prédire comment un gripper interagira avec l'objet lors de la préhension. Pour une bouteille cylindrique, le système pourrait suggérer de saisir sa partie centrale avec des mâchoires parallèles ; pour une assiette plate, il pourrait proposer une préhension par pincement sur le bord. Plus récemment, des réseaux adversaires génératifs (GANs) ont été utilisés pour générer des candidats à la préhension diversifiés et réalistes en apprenant à partir de grands ensembles de données de préhensions réussies.
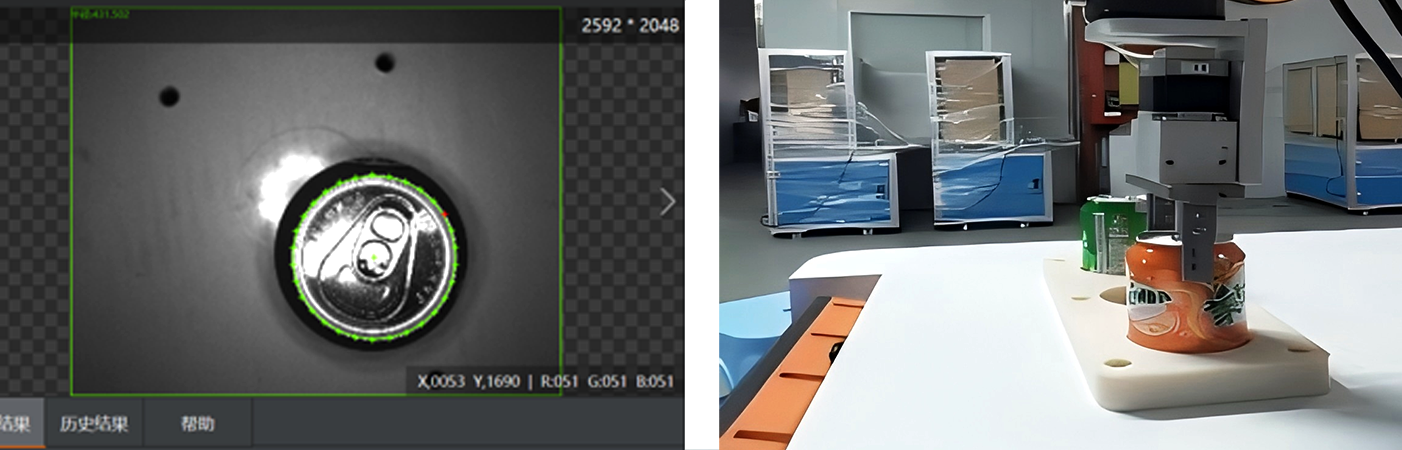
Évaluation de la qualité de la préhension : Chaque prise candidate est évaluée en termes de stabilité (par exemple, si l'objet va glisser), de faisabilité (par exemple, si l'étreinte du robot peut atteindre la position sans entrer en collision avec d'autres objets) et de sécurité (par exemple, en évitant les zones fragiles). Des modèles d'apprentissage automatique, formés sur des milliers d'exemples d'objets 3D, peuvent prédire quelles prises ont le plus de chances de réussir. L'apprentissage par renforcement a également montré un grand potentiel dans ce domaine, car les robots peuvent apprendre des stratégies de prise optimales par essais et erreurs dans des environnements simulés.
3. Exécution robotique et retour d'information
Le robot utilise son gripper ou son effecteur final pour exécuter la prise planifiée, guidé par une estimation précise de la position 3D pour s'aligner avec l'emplacement de l'objet. Différents types de grippers, tels que des grippers à mâchoires parallèles, des ventouses ou des mains multi-doigts, sont sélectionnés en fonction des caractéristiques de l'objet. Par exemple, les ventouses sont idéales pour les surfaces plates et non poreuses, tandis que les mains multi-doigts peuvent manipuler des objets irréguliers avec plus de dextérité.
Retour d'information en temps réel : Les capteurs (par exemple, des capteurs de force-torque ou des caméras de vision) fournissent un retour d'information instantané pendant la prise. Si l'objet bouge ou si le gripper glisse, le robot peut ajuster sa prise ou réessayer, améliorant ainsi la fiabilité dans des environnements en désordre. Certains systèmes avancés utilisent même des capteurs tactiles intégrés dans le gripper pour détecter la texture et la dureté de l'objet, permettant des stratégies de prise plus adaptatives. Par exemple, si le capteur détecte un objet fragile, le robot peut réduire la force de saisie pour éviter les dommages.
Défis de la prise non ordonnée
L'attrapage non ordonné en vision 3D rencontre des obstacles techniques importants :
Occultation et Encombrement : Lorsque les objets se chevauchent, il est difficile de les segmenter ou de reconstruire leur forme complète. Par exemple, un robot pourrait avoir du mal à distinguer une cuillère enfouie sous un tas de fourchettes. Des techniques avancées comme le rendu volumétrique ou le regroupement basé sur les graphes aident à résoudre ces ambiguïtés. Le rendu volumétrique peut créer un modèle 3D de toute la scène, permettant à l'algorithme d'analyser l'occupation spatiale des objets et d'identifier les éléments cachés. Le regroupement basé sur les graphes traite chaque objet ou nuage de points comme un nœud dans un graphe et utilise les relations entre les nœuds pour séparer les objets chevauchants. Cependant, ces méthodes rencontrent encore des défis lorsqu'elles doivent gérer des encombrements complexes et très denses.
Propriétés variées des objets : Les objets ayant des formes complexes (par exemple, des conteneurs creux), des matériaux flexibles (par exemple, du tissu) ou des surfaces réfléchissantes (par exemple, du verre) sont difficiles à percevoir avec précision. La fusion multi-capteurs (en combinant les données RGB, de profondeur et tactiles) et l'augmentation de données (en entraînant des modèles sur des variations simulées) permettent de résoudre ces problèmes. Par exemple, combiner les données de profondeur avec des capteurs infrarouges peut aider à mieux comprendre la forme des objets transparents, tandis que l'augmentation de données peut exposer les modèles d'apprentissage automatique à une grande variété d'apparences d'objets, améliorant ainsi leur capacité de généralisation.
Performance en temps réel : Traiter des données 3D en haute résolution et générer rapidement des plans de préhension suffisamment rapides pour la réponse robotique nécessite des algorithmes efficaces et une accélération matérielle (par exemple, GPU ou unités de calcul en périphérie). Cependant, atteindre des performances en temps réel tout en maintenant une grande précision dans des environnements complexes reste un défi important, surtout lorsqu'il s'agit de gérer de grands nuages de points ou des modèles 3D haute définition.

Applications et tendances futures
Automatisation industrielle : La prise non ordonnée révolutionne la logistique des entrepôts. Par exemple, des robots équipés de vision 3D peuvent saisir des objets au hasard dans des bacs pour les emballer, réduisant ainsi la dépendance au tri manuel. Des entreprises comme Amazon et Toyota ont déjà intégré de tels systèmes dans leurs chaînes d'approvisionnement. Dans la fabrication automobile, des robots avec des capacités de prise non ordonnée peuvent manipuler des pièces directement depuis un stockage en vrac, optimisant ainsi les lignes de production et augmentant la flexibilité.
Frontières de la Recherche :
Gestion Multi-Objets : Développer des stratégies pour saisir plusieurs objets à la fois ou réorganiser le désordre pour accéder aux objets cachés. Cela pourrait impliquer des algorithmes avancés de planification de mouvement qui prennent en compte les interactions entre plusieurs objets lors de la saisie et de la manipulation.
Collaboration Homme-Robot : S'assurer que les robots peuvent naviguer en toute sécurité et saisir des objets dans des espaces partagés, en s'adaptant aux mouvements humains et aux obstacles imprévisibles. Cela nécessite des systèmes de perception sophistiqués capables de distinguer entre les humains et les objets, ainsi que des algorithmes de planification de mouvement en temps réel qui priorisent la sécurité.
Conclusion
L'attrapage non ordonné en vision 3D représente une percée critique pour la robotique autonome, permettant aux machines d'interagir avec le monde désordonné et non structuré comme le font les humains. En intégrant une perception avancée, une planification intelligente et une exécution adaptative, cette technologie améliore l'efficacité dans les industries et ouvre des portes à des robots de service plus polyvalents. À mesure que les capteurs 3D deviennent moins coûteux et que les modèles d'apprentissage automatique gagnent en robustesse, l'attrapage non ordonné débloquera de nouvelles possibilités en automatisation, rendant les robots plus performants, fiables et prêts pour le monde réel. Les recherches et développements continus dans ce domaine promettent de redessiner l'avenir de la robotique, de l'automatisation industrielle à l'assistance quotidienne, en permettant aux robots de gérer les complexités des environnements non structurés avec facilité.





