

3Dビジョンにおける無順序把持とは何ですか?
ロボティクスとコンピュータビジョンの分野で、 無秩序把持 非構造化で混乱した環境から物体を識別し、その配置や姿勢に関する事前の知識なしに物体を把持するロボットシステムの能力を指します。順序のある把持(ordered grasping)では、物体が整然と並べられたり予測可能な方向で提示されたりします(例:コンベアベルト上)。一方、非順序把持は、ビンの中に積まれた物体の山、机上に散らばったアイテム、または倉庫でランダムに積み上げられた製品など、現実世界の混沌としたシナリオに対処します。この技術は、自動化されたビンピッキング、物流ソーティング、適応型ロボット操作などのアプリケーションにとって重要です。産業界がより高度な自動化を目指し、ロボットが制御された環境を超えていく中で、非順序把持は真の自律的なロボット操作を実現するための基盤となっています。
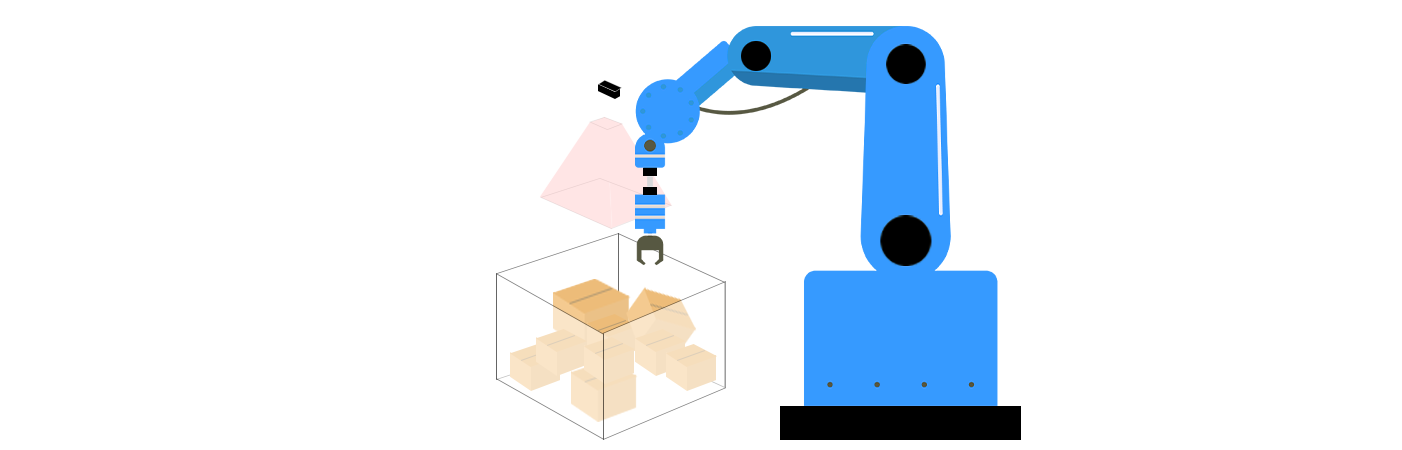
3Dビジョンにおける非順序把持の主要な構成要素
非順序把持は 3Dビジョン技術 および ロボティクスアルゴリズム 3つの主要な課題を解決するために:認識、把持計画、および実行。これらのコンポーネントは協調して動作し、ロボットが周囲環境を理解し、物体とどのように最適に相互作用するかを決定し、精密なアクションを実行できるようにします。
1. 3D認識とシーン理解
深度センシング : 3Dビジョンシステムは、LiDAR、構造化光カメラ、またはステレオカメラなどのセンサーを使用して深度情報を取得し、雑然としたシーンの点群や3Dモデルを作成します。例えば、LiDARはレーザー光を物体に発射し、それが物体から反射してセンサーに戻る時間を測定することで距離を計算します。構造化光カメラはパターンを物体に投影し、そのパターンがどう歪むかを分析して深度を推定します。また、ステレオカメラは人間の両眼視覚を模倣し、2つのレンズを使用して距離を三角測量します。
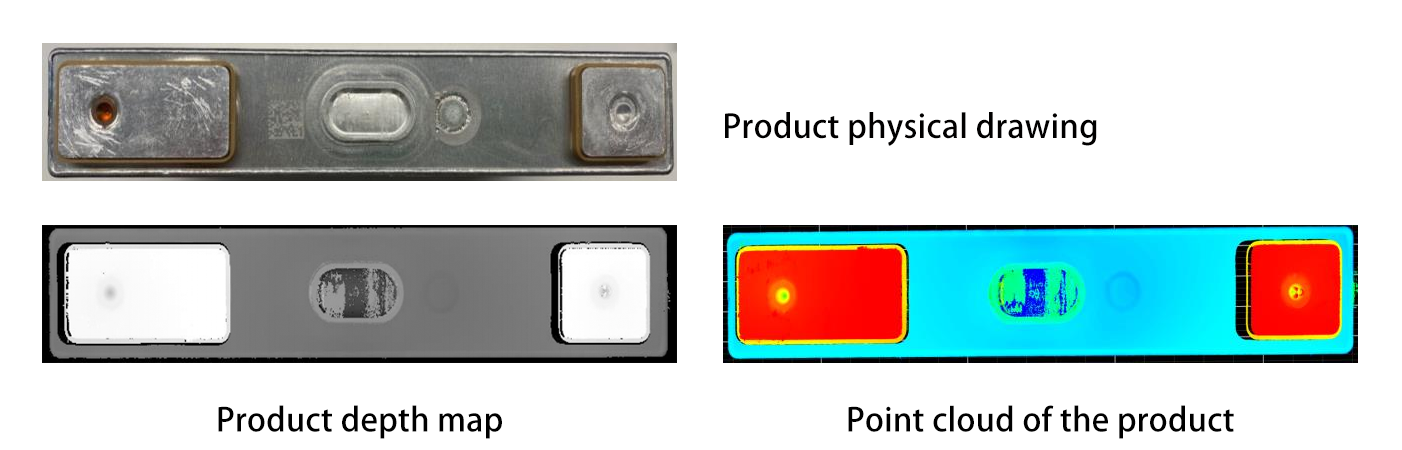
物体セグメンテーションと認識 : 先進的なアルゴリズム(例:PointNetやMask R-CNNなどのディープラーニングモデル)は、3Dデータを処理して、混雑した環境から個々の物体を分離し識別します。PointNetは3Dディープラーニングの先駆けであり、点群データを正規のグリッドに変換することなく直接処理することができ、これにより物体の幾何学的特徴を元の形式で理解できます。一方、Mask R-CNNは人気のあるFaster R-CNNフレームワークを拡張したもので、3Dにおけるインスタンスセグメンテーションに対応し、ロボットが複雑なシーンから特定の物体を区別して分離できるようにします。例えば、ロボットは幾何学的特徴や表面の質感を分析することで、ごちゃまぜになったビンの中から金属部品とプラスチック部品を区別することができます。さらに、セマンティックセグメンテーションのような手法を使用すると、物体の異なる部分にラベルを付けることができ、これは把持に適した領域を特定するのに役立ちます。
2. 3D空間での把持計画
物体が識別されると、ロボットはどこをどのように把持するかを決定する必要があります:
把持候補の生成 アルゴリズムは、物体の形状、サイズ、物理的特性に基づいて潜在的な把持姿勢を生成します。幾何学的なアプローチでは、物体の凸包を解析して安定した接触点を見つけようとする一方で、物理学ベースのシミュレーションでは、把持中にグリッパーが物体とどのように相互作用するかを予測できます。円筒形のボトルの場合、システムは平行なジョーでその中央部を把持することを提案するかもしれません。平らな皿の場合、端をつまむような把持を提案するかもしれません。最近では、生成対抗ネットワーク(GAN)が、成功した把持の大量のデータセットから学習することで、多様で現実的な把持候補を生成するために使用されるようになりました。
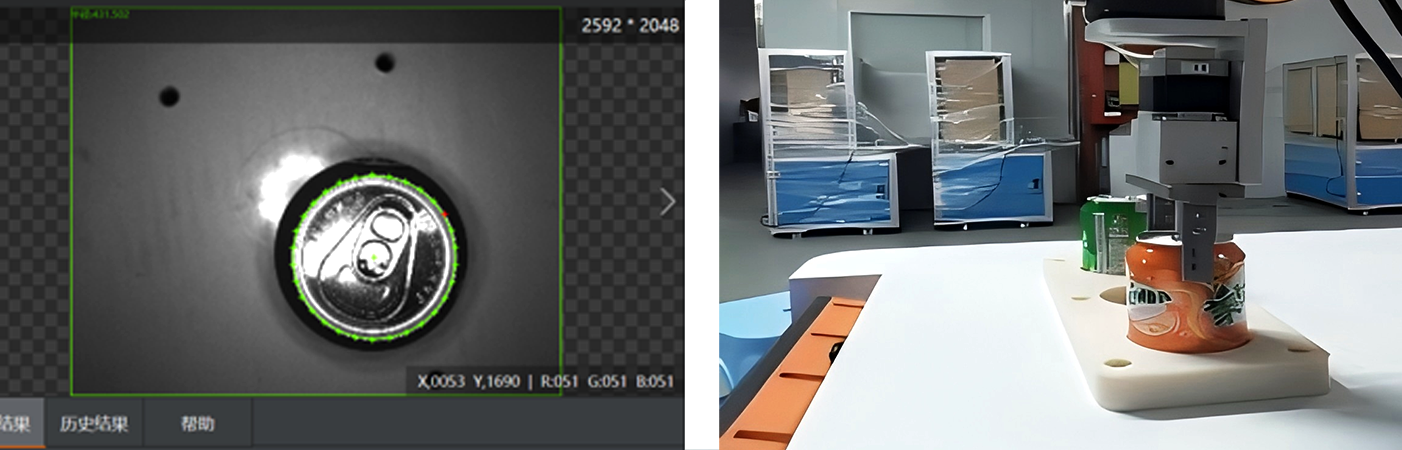
把持品質評価 : 各候補のグリップは、安定性(例:物体が滑らないかどうか)、実現可能性(例:ロボットのグリッパーが他の物体と衝突せずに姿勢を取れるかどうか)、安全性(例:脆い領域を避けるかどうか)について評価されます。何千もの3Dオブジェクトの例に基づいて訓練された機械学習モデルは、どのグリップが最も成功する可能性が高いかを予測できます。強化学習もこの分野で大きな可能性を示しており、ロボットはシミュレーション環境での試行錯誤を通じて最適なグリップ戦略を学ぶことができます。
3. ロボットの実行とフィードバック
ロボットはグリッパーやエンドエフェクタを使用して計画された把持を実行します。これは、物体の位置に合わせるために精密な3D姿勢推定によって案内されます。平行ジョー式グリッパー、吸着カップ、または多指ハンドなど、異なる種類のグリッパーは、物体の特性に基づいて選択されます。例えば、吸着カップは平坦で非多孔性の表面に理想的ですが、多指ハンドは不規則な形状の物体をより器用に扱うことができます。
リアルタイムフィードバック センサー(例: フォーストルクセンサーやビジョンカメラ)は把持中に即時フィードバックを提供します。物体が動いたりグリッパーが滑ったりした場合、ロボットはその把持を調整したり再試行したりして、混乱した環境での信頼性を向上させます。一部の高度なシステムでは、グリッパーに埋め込まれた触覚センサーを使用して、物体の質感や硬さを感知し、より適応的な把持戦略を可能にします。例えば、センサーが繊細な物体を検知した場合、ロボットは損傷を避けるために把持力を減らすことができます。
順不同把持における課題
3Dビジョンにおける無秩序な把持は、大きな技術的課題に直面しています:
オクルージョンとクラッタ :物体が重なり合う場合、それらをセグメンテーションしたり、完全な形状を再構築することが困難です。例えば、フォークの山の下に埋もれたスプーンをロボットが識別するのは難しいかもしれません。体積レンダリングやグラフベースのクラスタリングなどの高度な技術は、これらの曖昧さを解消するのに役立ちます。体積レンダリングはシーン全体の3Dモデルを作成し、アルゴリズムが物体の空間占有を分析して隠れたアイテムを特定できるようにします。グラフベースのクラスタリングは、各物体やポイントクラウドをグラフ内のノードとして扱い、ノード間の関係を使って重なり合う物体を分離します。しかし、これらの方法でも、非常に複雑で密集したクラッタに対処する際には依然として課題があります。
多様な物体の特性 複雑な形状の物体(例:中空の容器)、柔軟な素材(例:布地)、または反射する表面(例:ガラス)は、正確に認識するのが難しい。マルチセンサ融合(RGB、深度、触覚データを組み合わせること)とデータ拡張(シミュレーションによる変化を用いたモデルの学習)がこれらの問題に対処します。例えば、深度データを赤外線センサと組み合わせることで、透明な物体の形状をよりよく理解できるようになり、データ拡張は機械学習モデルに多様な物体の外観を学ばせ、その汎化能力を向上させます。
リアルタイムパフォーマンス 高解像度の3Dデータを処理し、ロボットの応答に十分速いグリップ計画を生成するには、効率的なアルゴリズムとハードウェアの加速(例:GPUやエッジコンピューティングユニット)が必要です。しかし、大規模なポイントクラウドや高精細3Dモデルを扱う場合、特に複雑な環境において、高い精度を維持しながらリアルタイム性能を達成することは依然として大きな課題です。

応用と将来の傾向
産業オートメーション : 無秩序な把持が倉庫ロジスティクスを革新しています。例えば、3Dビジョンを搭載したロボットは、包装のためにコンテナからランダムなアイテムを取り出すことができ、手作業による仕分けへの依存を減らします。アマゾンやトヨタなどの企業はすでにそのようなシステムをサプライチェーンに統合しています。自動車製造においても、無秩序な把持能力を持つロボットは、バルク保管から部品を取り扱うことができ、生産ラインを効率化し、柔軟性を高めます。
リサーチフロンティア :
複数物体把持 : 複数の物体を一度に把持する戦略や、隠れた物体にアクセスするために散乱を再配置する技術を開発しています。これは、把持や操作中に複数の物体間の相互作用を考慮する高度な動作計画アルゴリズムを含むことがあります。
ヒューマンロボットコラボレーション : 共有空間でロボットが安全に移動し、物体を把持できるようにすることを目指します。これには、人間の動きや予測不可能な障害物に適応する必要があります。高度な認識システムによって、人間と物体を区別できなければならず、安全性を優先するリアルタイムの動作計画アルゴリズムも必要です。
結論
3Dビジョンにおける無秩序な把持は、自律型ロボット工学にとって重要な突破であり、機械が人間と同じように不規則で構造のない世界と対話できるようにします。高度な認識、知能的な計画立案、適応的な実行を統合することで、この技術は産業での効率を向上させ、より多機能なサービスロボットの扉を開きます。3Dセンサーが安くなり、機械学習モデルがより堅牢になるにつれて、無秩序な把持は自動化において新しい可能性を解き放ち、ロボットをより強力で信頼性が高く、現実世界に適応できるものにします。この分野での継続的な研究開発は、工業用自動化から日常の支援まで、ロボットが非構造化環境の複雑さを簡単に処理できる力を与えることで、ロボティクスの未来を再定義することを約束します。





