

Vad är oordnad greppning i 3D-vision?
Inom robotik och datorseende, oordnad greppning syftar till en robot系统的 förmåga att identifiera och greppa objekt från ostrukturerade, kladdiga miljöer utan tidigare kunskap om deras ordning eller ställning. Åt skillnaden från "ordnad greppning", där objekten är snyggt justerade eller presenterade i förutsägba orienteringar (t.ex., på en transportbälte), hanterar ostrukturad greppning kaoset i verkliga livsscenarier – som högar av objekt i en korg, spridda föremål på en skrivbord, eller slumpmässigt staplade produkter i ett lager. Denna teknik är avgörande för tillämpningar som automatisk korgplockning, logistiksortering, och anpassad robotmanipulation. Som industrier strävar efter större automatisering och robotar går utöver kontrollerade miljöer, har ostrukturad greppning dykt upp som en hörnsten för att uppnå verkligen autonom robotoperation.
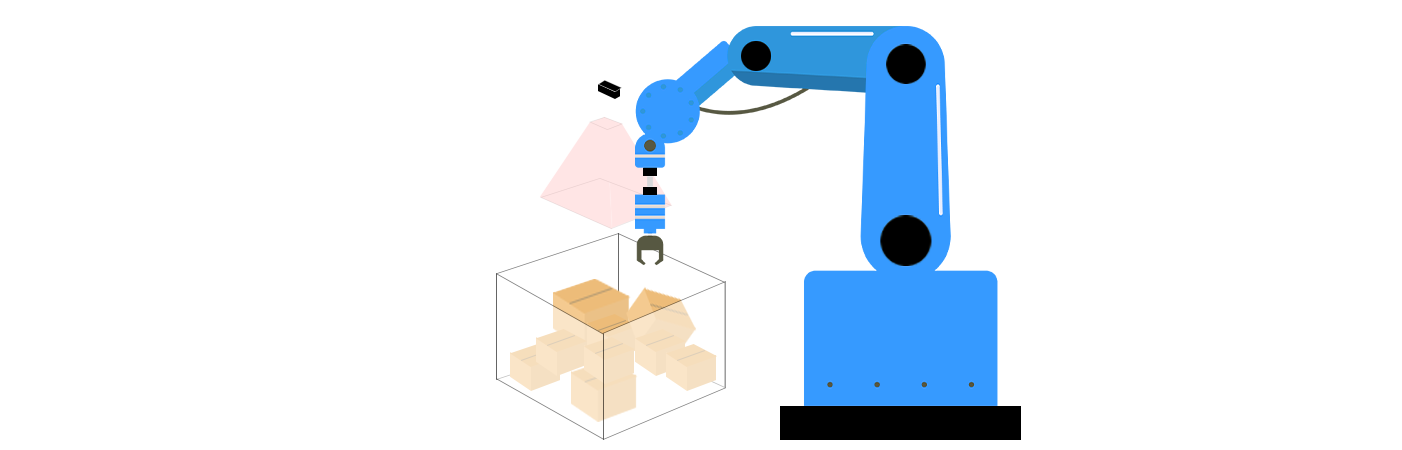
Kärnkomponenter i ostrukturad greppning inom 3D-vision
Ostrukturad greppning kombinerar 3D-visionstekniker och robotiksalgoritmer att lösa tre nyckelutmaningar: perception, greppningsplanering och exekvering. Dessa komponenter fungerar tillsammans för att låta robotar förstå sin omgivning, avgöra den bästa metoden att interagera med objekt och utföra handlingar med precision.
1. 3D-perception och scenförståelse
Djupdetektering : 3D-visionssystem använder sensorer som LiDAR, strukturerade ljuskameror eller stereokameror för att fånga djupinformation, skapa punktmoln eller 3D-modeller av det klumpiga scenariot. LiDAR emitterar till exempel laserskepper som studsar av objekt och återvänder till sensorn, vilket beräknar avstånd baserat på tid-i-flygt-principen. Strukturerade ljuskameror projicerar mönster på objekt och analyserar hur dessa mönster deformeras för att inferera djup, medan stereokameror imiterar människors binöjd syn genom att använda två linser för att triangulera avstånd.
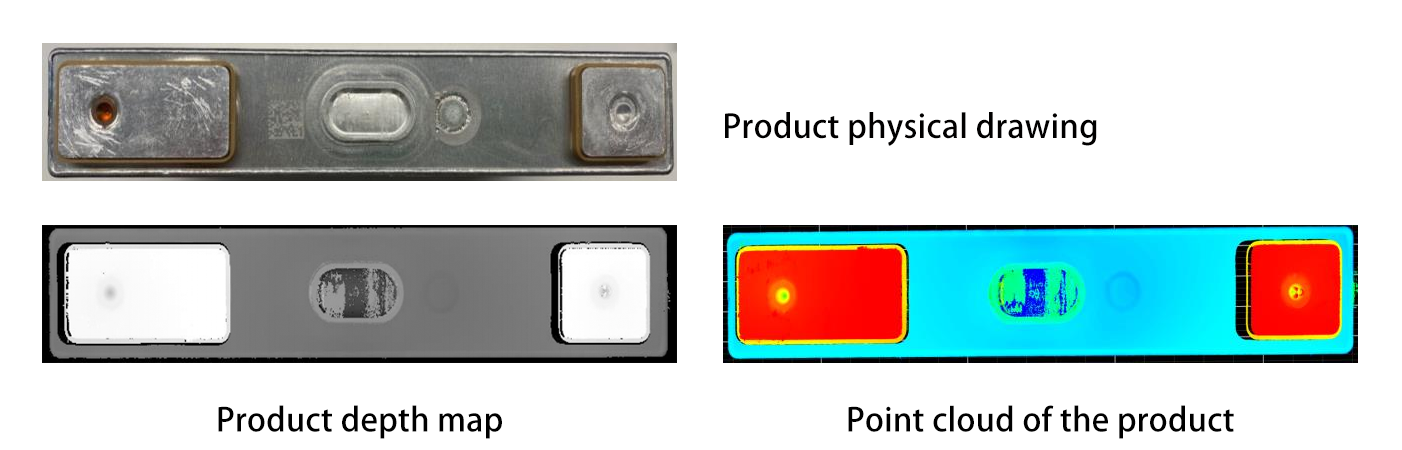
Objektsegmentering och -igenkänning : Avancerade algoritmer (t.ex., djupinlärningsmodeller som PointNet eller Mask R-CNN) bearbetar 3D-data för att skilja enskilda objekt från oordning och identifiera dem. PointNet, en pioneer inom 3D-djupinlärning, bearbetar punktmolndata direkt utan att konvertera det till ett regelbundet rutnät, vilket gör det möjligt att förstå de geometriska egenskaperna hos objekt i deras ursprungliga format. Mask R-CNN utökar däremot den populära Faster R-CNN-ramverket för att hantera instanssegmentering i 3D, vilket låter robotar skilja och isolera specifika objekt från komplexa scener. Till exempel kan en robot skilja en metallkomponent från en plastdel i en kaosburk genom att analysera deras geometriska egenskaper eller yttextrukture. Dessutom kan tekniker som semantisk segmentering märka olika delar av ett objekt, vilket är användbart för att identifiera områden som är lämpliga att greppa.
2. Greppsplanering i 3D-rum
När objekten har identifierats måste roboten avgöra var och hur den ska greppa dem:
Generering av greppkandidater : Algoritmer genererar potentiella greppningspositioner baserat på ett objekts form, storlek och fysiska egenskaper. Geometriska metoder kan analysera det konvexa höljet av ett objekt för att hitta stabila kontaktpunkter, medan fysikbaserade simuleringar kan förutsäga hur en greppare kommer att interagera med objektet under ett tag. För en cylindrisk flaska kanske systemet föreslår att greppa dess midjesektion med parallella käftar; för en platt tallrik kanske det föreslår en knepgreppning på kanten. Senare har generativa motståndsnätverk (GANs) använts för att generera mångfaldiga och realistiska greppkandidater genom att lära sig från stora datamängder av framgångsrika grepp.
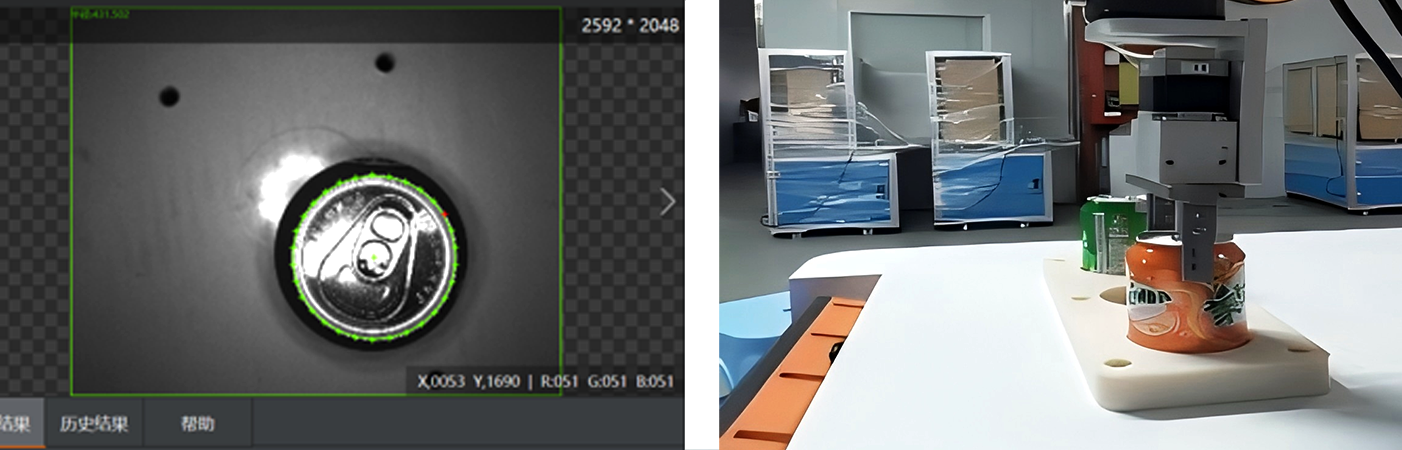
Värdering av Greppkvalitet : Varje kandidatgrepp utvärderas för stabilitet (t.ex., om objektet kommer att glida), möjliggörande (t.ex., om robotens greppare kan nå ställningen utan att kollidera med andra objekt), och säkerhet (t.ex., undvika fragila områden). Maskininlärningsmodeller, tränade på tusentals 3D-objektexempel, kan förutsäga vilka grepp som är mest sannolika att lyckas. Förstärkningsinlärning har också visat stor potential inom detta område, eftersom robotar kan lära sig optimala greppstrategier genom försök och fel i simulerade miljöer.
3. Robotisk utförande och återkoppling
Roboten använder sin greppare eller sluteffektor för att utföra den planerade greppningen, guidad av precist 3D-påläggningsskattning för att alignera med objektets position. Olika typer av greppare, som parallellkäkk-greppare, sugkoppar eller flerfingrade händer, väljs utifrån objektets egenskaper. Till exempel är sugkoppar idealiska för platta, icke-porösa ytor, medan flerfingrade händer kan hantera oregelbundna objekt med större färdighet.
Feedback i realtid sensorer (t.ex., kraft-torque-sensorer eller visionskameror) ger omedelbar feedback under greppningen. Om objektet rör sig eller grepparen glider, kan roboten justera sitt grepp eller försöka igen, vilket förbättrar tillförlitligheten i kaotiska miljöer. Några avancerade system använder till och med taktila sensorer inbyggda i grepparen för att upptäcka objektets textur och hårdhet, vilket möjliggör mer anpassade greppningsstrategier. Om sensorn till exempel upptäcker ett känsligt objekt, kan roboten minska greppskraften för att undvika skada.
Utmaningar vid oordnad greppning
Oordnad greppning inom 3D-vision stöter på betydande tekniska hinder:
Occlusion och Klottrighet : När objekt överlappar varandra är det svårt att segmentera dem eller återskapa deras fullständiga form. Till exempel kan en robot ha problem med att skilja en sked som är begraven under en hög med gafflar. Avancerade tekniker som volymrendering eller grafbaserad klusteranalys hjälper till att lösa dessa osäkerheter. Volymrendering kan skapa en 3D-modell av hela sceneriet, vilket låter algoritmen analysera objektens rumsupptagande och identifiera dolda föremål. Grafbaserad klusteranalys behandlar varje objekt eller punktmoln som en nod i en graf och använder relationerna mellan noderna för att separera överlappande objekt. Dock möter fortfarande dessa metoder utmaningar när de hanterar höggradigt komplexa och tätt packade klottrigheter.
Diverse föremåls egenskaper : Föremål med komplexa former (t.ex., hölga behållare), flexibla material (t.ex., stoff) eller reflekterande ytor (t.ex., glas) är svåra att uppfatta korrekt. Multisensorfusion (att kombinera RGB, djup och taktil data) och dataaugmentering (träna modeller på simulerade variationer) löser dessa problem. Till exempel kan kombinationen av djupdata med infrarödsensorer hjälpa till att förbättra förståelsen av formen på genomskinliga föremål, medan dataaugmentering exponerar maskininlärningsmodeller för en bred variety av föremålsutseenden, vilket förbättrar deras generaliseringsförmåga.
Realtidsspelarverkan : Att bearbeta högupplöst 3D-data och generera greppplaner snabbt nog för roboters svar kräver effektiva algoritmer och hårdvarubeschleunigning (t.ex., GPU:er eller edge computing-enheter). Dock är det fortfarande en stor utmaning att uppnå realtidprestanda samtidigt som man bevarar hög noggrannhet i komplexa miljöer, särskilt när man hanterar stora punktmoln eller högupplösta 3D-modeller.

Användning och framtida trender
Industriell Automation : Oordnad greppning revolutionerar lagerlogistik. Till exempel kan robotar utrustade med 3D-vision plocka slumpmässiga föremål från containrar för packning, vilket minskar beroendet av manuellt sorteringsarbete. Företag som Amazon och Toyota har redan integrerat sådana system i sina leveranskedjor. Inom bilproduktion kan robotar med möjlighet till oordnad greppning hantera delar direkt från masslagring, vilket förenklar produktionslinjer och ökar flexibiliteten.
Forskningsfronten :
Flerspisshantering : Att utveckla strategier för att greppa flera objekt samtidigt eller omorganisera kaos för att få tillgång till dolda föremål. Detta kan involvera avancerade rörelseplaneringsalgoritmer som tar hänsyn till interaktionerna mellan flera objekt under greppningen och manipulationen.
Människa-robot-samarbete : Att säkerställa att robotar kan navigera och greppa objekt i delade utrymmen, anpassa sig till människors rörelser och oväntade hinder. Detta kräver sofistikerade perceptionsystem som kan skilja mellan människor och objekt, samt algoritmer för realtids-rörelseplanering som prioriterar säkerhet.
Slutsats
Oordnad greppning i 3D-vision är en avgörande genombrott för autonom robotik, vilket möjliggör för maskiner att interagera med det oordnade, ostrukturerade världen på samma sätt som människor gör. Genom att integrera avancerad perception, intelligent planering och anpassningsbar utförande drivs effektivitet i industrier och öppnar dörrar till mer versatila servicebotar. När 3D-sensorer blir billigare och maskininlärningsmodeller mer robusta kommer oordnad greppning att låsa upp nya möjligheter inom automatisering, vilket gör robotar mer kapabla, pålitliga och beredda för den verkliga världen. Den pågående forskningen och utvecklingen inom detta område lovar att omforma framtiden för robotik, från industriell automatisering till daglig hjälp, genom att ge robotar möjlighet att hantera de komplexiteter som finns i ostrukturerade miljöer enkelt.





