

Dos Tipos de Algoritmos para Visión Artificial
La visión por computadora se ha convertido en un pilar de la automatización industrial, permitiendo un control de calidad eficiente y la detección de defectos. En su núcleo, la visión por computadora depende de algoritmos para replicar el juicio visual humano. Estos algoritmos pueden clasificarse en dos tipos principales: sistemas basados en reglas y algoritmos de aprendizaje profundo . Comprender sus principios, fortalezas y limitaciones es crucial para optimizar sus aplicaciones en escenarios del mundo real.
Sistemas basados en reglas
Algoritmos basados en reglas: Estos sistemas analizan características específicas de un objeto, como el color, la forma o los valores en escala de grises, y los comparan con umbrales o patrones establecidos. Por ejemplo:
- Una hoja de papel blanca con manchas puede ser marcada como defectuosa porque las manchas muestran un valor en escala de grises distinto del fondo.
- Un producto que carece de un logotipo estándar (un patrón predefinido) se considera (no conforme) a través del emparejamiento de plantillas.

Ventajas :
Facilidad de implementación las reglas son sencillas de programar una vez que los patrones de características están bien definidos.
Bajo costo computacional : Requisitos mínimos de hardware debido a cálculos deterministas.
Limitaciones :
Demandas ambientales rígidas : La iluminación, los ángulos de la cámara y la posición del producto deben mantenerse altamente consistentes.
Adaptabilidad limitada : Incluso pequeñas variaciones en la apariencia del producto (por ejemplo, fluctuaciones en la textura del material) o defectos irregulares (por ejemplo, arañazos aleatorios) pueden llevar a juicios erróneos.
En la práctica, los sistemas basados en reglas se destacan en entornos altamente controlados donde las especificaciones del producto y las condiciones de inspección están estrictamente estandarizadas. Sin embargo, su fragilidad se vuelve evidente en entornos dinámicos o impredecibles.
Algoritmos de Aprendizaje Profundo: Aprendiendo de la Complejidad
El aprendizaje profundo imita los procesos cognitivos humanos entrenando redes neuronales con grandes conjuntos de datos. A diferencia de los sistemas basados en reglas, estos algoritmos extraen características de las imágenes de manera autónoma, lo que les permite manejar escenarios complejos como:
Detectar defectos irregulares (por ejemplo, grietas o manchas de forma aleatoria).
Diferenciación de objetos en fondos llenos de desorden.

Ventajas :
Alta precisión en entornos caóticos : Se adapta a variaciones en la iluminación, ángulos e inconsistencias en los productos.
Generalización : Una vez entrenados, los modelos pueden reconocer patrones de defectos novedosos dentro de las categorías aprendidas.
Desafíos :
Hambre de datos : El entrenamiento requiere cientos a miles de imágenes etiquetadas, con una fuerte dependencia de muestras defectuosas. En la fabricación, los defectos suelen ser raros, lo que exige fases prolongadas de recolección de datos (semanas a meses).
Problemas de escalabilidad : Cambiar a una nueva especificación de producto generalmente requiere volver a entrenar desde cero, aumentando los costos de tiempo y recursos.
Elegir la herramienta adecuada: el contexto importa
La elección entre algoritmos basados en reglas y de aprendizaje profundo depende de casos de uso específicos:
Sistemas basados en reglas se destacan en la producción en alto volumen y estandarizada (por ejemplo, componentes de semiconductores) donde se garantiza la consistencia.
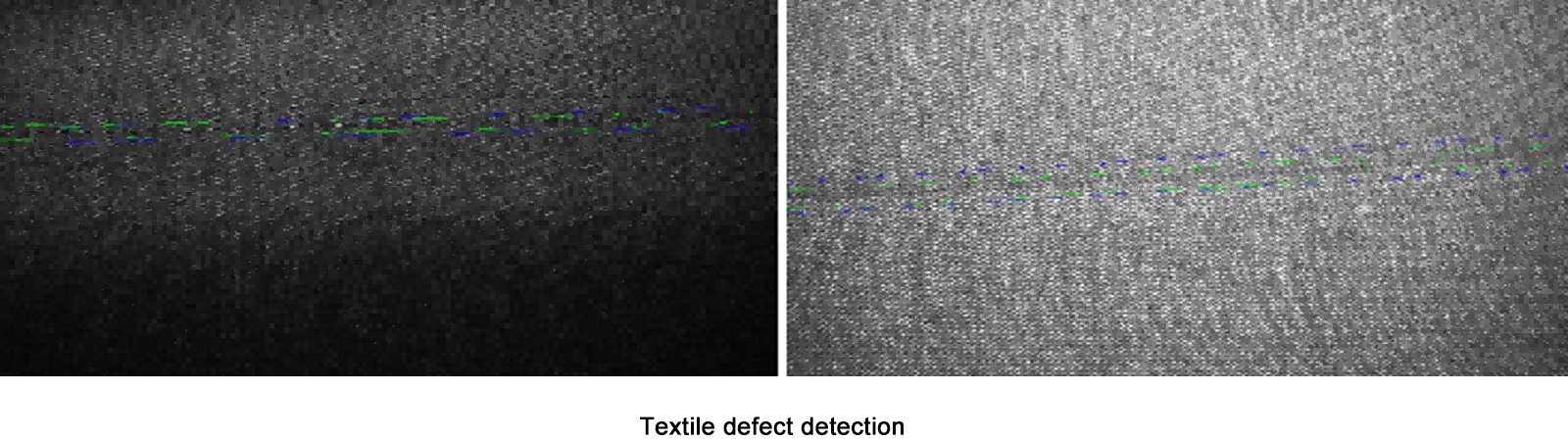
Aprendizaje profundo brilla en escenarios de bajo volumen y alta variabilidad (por ejemplo, detección de defectos en textiles) o cuando los defectos no tienen patrones predecibles.
Cabe destacar que están emergiendo enfoques híbridos. Por ejemplo, los filtros basados en reglas pueden preprocesar imágenes para reducir las cargas de trabajo de aprendizaje profundo, mientras que las herramientas de generación de datos sintéticos alivian las carencias de muestras de entrenamiento.
Conclusión
La efectividad de la visión por computadora depende de alinear las capacidades algorítmicas con las realidades operativas. Los sistemas basados en reglas ofrecen simplicidad y velocidad, pero fallan en entornos impredecibles. El aprendizaje profundo proporciona flexibilidad y precisión, pero exige una inversión significativa inicial. En última instancia, la estabilidad de cualquier sistema se centra en tres factores: la uniformidad del producto, el control ambiental y la diversidad de muestras. Dominar estas variables asegura que la visión por computadora cumpla con su promesa de precisión y fiabilidad.





