

Cos'è la Presa Non Ordinata nella Visione 3D?
Nel campo della robotica e della visione artificiale, agguantamento non ordinato si riferisce alla capacità di un sistema robotico di identificare e afferrare oggetti da ambienti non strutturati e ingombri senza una conoscenza preventiva del loro assetto o posizione. A differenza dell'"afferramento ordinato", dove gli oggetti sono allineati in modo ordinato o presentati in orientamenti prevedibili (ad esempio, su una cinghia trasportatrice), l'afferramento non ordinato gestisce il caos delle situazioni reali - come mucchi di oggetti in un contenitore, oggetti sparsi su una scrivania, o prodotti impilati casualmente in un magazzino. Questa tecnologia è fondamentale per applicazioni come il prelievo automatico da contenitori, la classificazione logistica e la manipolazione robotica adattiva. Man mano che le industrie mirano a una maggiore automazione e i robot si muovono al di là degli ambienti controllati, l'afferramento non ordinato è emerso come pilastro per raggiungere operazioni robotiche completamente autonome.
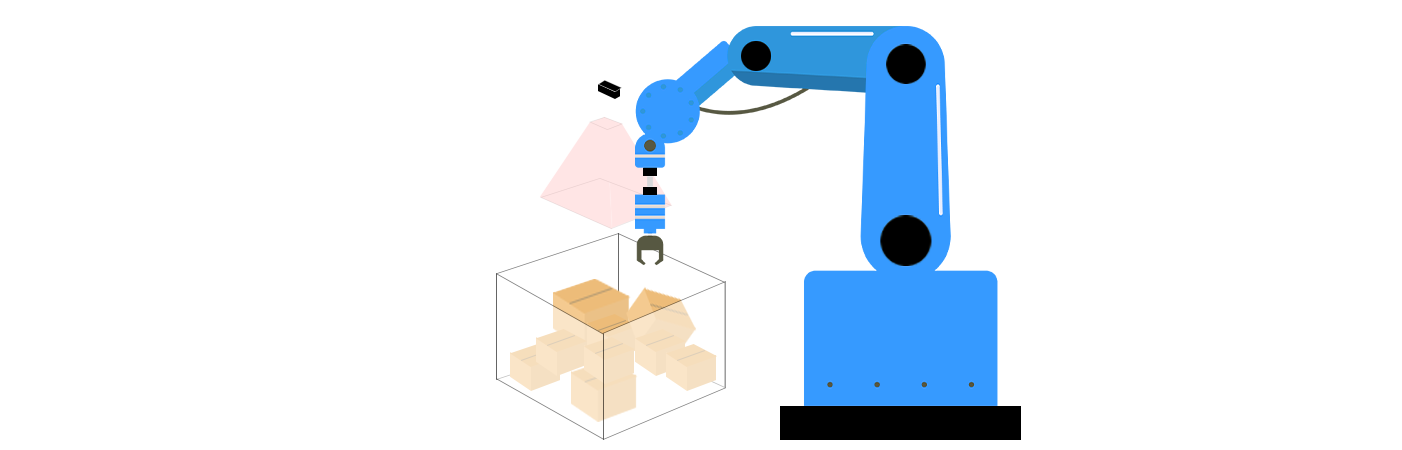
Componenti principali dell'afferramento non ordinato nella visione 3D
L'afferramento non ordinato combina tecnologie di visione 3D e algoritmi robotici per risolvere tre sfide chiave: percezione, pianificazione della presa e esecuzione. Questi componenti lavorano in tandem per consentire ai robot di comprendere il loro ambiente, determinare il modo migliore per interagire con gli oggetti e eseguire azioni con precisione.
1. percezione 3D e Comprensione della Scena
Rilevamento della Profondità : i sistemi di visione 3D utilizzano sensori come LiDAR, camere a luce strutturata o camere stereo per catturare informazioni sulla profondità, creando nubi di punti o modelli 3D della scena ingombra. Ad esempio, il LiDAR emette fasci laser che rimbalzano sugli oggetti e ritornano al sensore, calcolando le distanze in base al principio del time-of-flight. Le camere a luce strutturata proiettano schemi sugli oggetti e analizzano come questi schemi si deformano per inferire la profondità, mentre le camere stereo mimano la visione binoculare umana utilizzando due lenti per triangolare le distanze.
Segmentazione e Riconoscimento degli Oggetti : Algoritmi avanzati (ad esempio, modelli di deep learning come PointNet o Mask R-CNN) elaborano i dati 3D per separare oggetti individuali dal disordine e identificarli. PointNet, un pioniere nel campo dell'apprendimento profondo 3D, elabora direttamente i dati del cloud di punti senza convertirli in una griglia regolare, permettendogli di comprendere le caratteristiche geometriche degli oggetti nel loro formato originale. Mask R-CNN, d'altra parte, estende il framework Faster R-CNN popolare per gestire la segmentazione istantanea in 3D, consentendo ai robot di distinguere e isolare oggetti specifici da scene complesse. Ad esempio, un robot potrebbe distinguere una parte metallica da un componente in plastica in un contenitore ingarbugliato analizzando le loro caratteristiche geometriche o le texture della superficie. Inoltre, tecniche come la segmentazione semantica possono etichettare diverse parti di un oggetto, il che è utile per identificare aree adatte alla presa.
2. Pianificazione della Presa nello Spazio 3D
Una volta identificati gli oggetti, il robot deve determinare dove e come afferrarli:
Generazione di Candidati per la Presa : Algoritmi generano pose di presa potenziali in base alla forma, dimensione e proprietà fisiche di un oggetto. Approcci geometrici potrebbero analizzare l'inviluppo convesso di un oggetto per trovare punti di contatto stabili, mentre simulazioni basate sulla fisica possono prevedere come un presa interagirà con l'oggetto durante la presa. Per una bottiglia cilindrica, il sistema potrebbe suggerire di afferrarne la parte centrale con mascelle parallele; per una piastra piatta, potrebbe proporre una presa a pizzico sul bordo. Più recentemente, sono state impiegate reti generative avversarie (GAN) per generare candidati di presa diversi e realistici imparando da grandi dataset di prese riuscite.
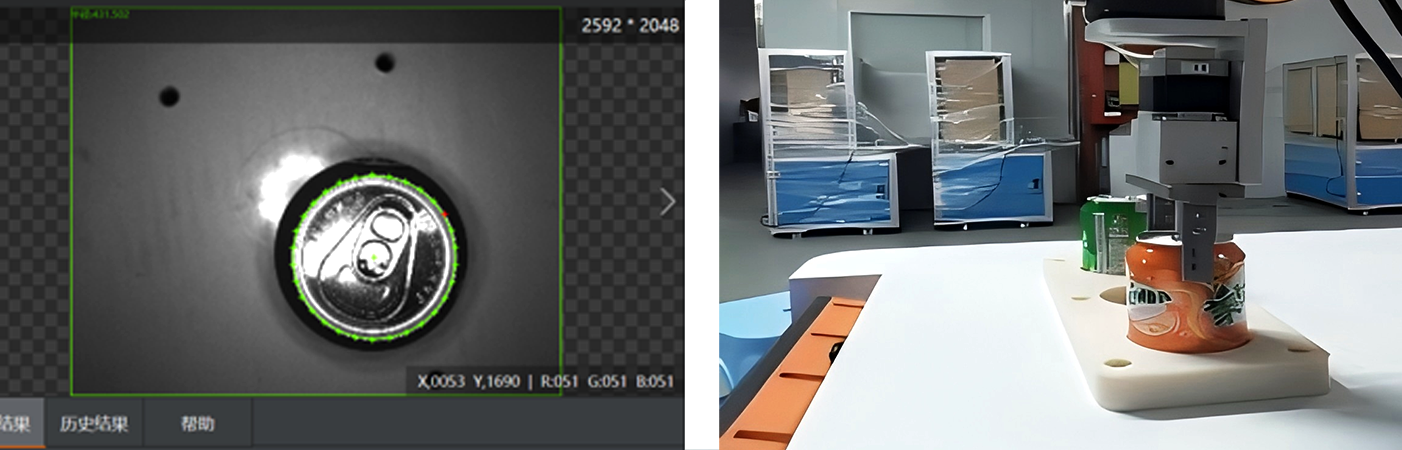
Valutazione della Qualità della Presa : Ogni presa candidata viene valutata per stabilità (ad esempio, se l'oggetto scivolerà), fattibilità (ad esempio, se il gripper del robot può raggiungere la posizione senza collisioni con altri oggetti) e sicurezza (ad esempio, evitando aree fragili). Modelli di machine learning, addestrati su migliaia di esempi di oggetti 3D, possono prevedere quali prese hanno maggiori probabilità di riuscire. L'apprendimento per rinforzo ha anche mostrato un grande potenziale in questo campo, poiché i robot possono imparare strategie di presa ottimali attraverso tentativi ed errori in ambienti simulati.
3. Esecuzione Robotica e Feedback
Il robot utilizza il suo gripper o end-effector per eseguire la presa pianificata, guidato da una stima precisa della posa 3D per allinearsi con la posizione dell'oggetto. Diversi tipi di gripper, come quelli a mascella parallela, tazze ad aspirazione o mani multi-dita, vengono selezionati in base alle caratteristiche dell'oggetto. Ad esempio, le tazze ad aspirazione sono ideali per superfici piatte e non porose, mentre le mani multi-dita possono gestire oggetti di forma irregolare con maggiore destrezza.
Feedback in tempo reale : I sensori (ad esempio, sensori forza-torques o camere di visione) forniscono un feedback istantaneo durante la presa. Se l'oggetto si sposta o il gripper scivola, il robot può ajustare la sua presa o riprovare, migliorando la affidabilità in ambienti disordinati. Alcuni sistemi avanzati utilizzano persino sensori tattili incorporati nel gripper per rilevare la texture e la durezza dell'oggetto, consentendo strategie di presa più adattive. Per esempio, se il sensore rileva un oggetto delicato, il robot può ridurre la forza di presa per evitare danni.
Sfide nella Presa Non Ordinata
La presa non ordinata in visione 3D si confronta con ostacoli tecnici significativi:
Occlusione e Ingombro : Quando gli oggetti si sovrappongono, è difficile segmentarli o ricostruire la loro forma completa. Ad esempio, un robot potrebbe faticare a distinguere un cucchiaio sepolto sotto un mucchio di forchette. Tecniche avanzate come il rendering volumetrico o il clustering basato su grafi aiutano a risolvere queste ambiguità. Il rendering volumetrico può creare un modello 3D della scena completa, consentendo all'algoritmo di analizzare l'occupazione spaziale degli oggetti e identificare elementi nascosti. Il clustering basato su grafi tratta ogni oggetto o nuvola di punti come un nodo in un grafo e utilizza le relazioni tra i nodi per separare oggetti sovrapposti. Tuttavia, questi metodi si trovano ancora ad affrontare sfide quando devono gestire ingombri complessi e densamente stipati.
Proprietà Variate degli Oggetti : Gli oggetti con forme complesse (ad esempio, contenitori cavi), materiali flessibili (ad esempio, tessuti) o superfici riflettenti (ad esempio, vetro) sono difficili da percepire in modo accurato. La fusione multi-sensore (combinando dati RGB, profondità e tattili) e l'augmentazione dei dati (allenando modelli su variazioni simulate) risolvono questi problemi. Ad esempio, combinare i dati di profondità con sensori a infrarossi può aiutare a comprendere meglio la forma degli oggetti trasparenti, mentre l'augmentazione dei dati può esporre i modelli di machine learning a una vasta gamma di aspetti degli oggetti, migliorandone la capacità di generalizzazione.
Prestazioni in tempo reale : Elaborare dati 3D ad alta risoluzione e generare piani di presa abbastanza velocemente per le risposte robotiche richiede algoritmi efficienti e accelerazione hardware (ad esempio, GPU o unità di calcolo periferico). Tuttavia, raggiungere prestazioni in tempo reale mantenendo un'alta precisione in ambienti complessi rimane ancora una sfida significativa, soprattutto quando si lavora con grandi nubi di punti o modelli 3D ad alta definizione.

Applicazioni e Future Tendenze
Automazione industriale : La presa non ordinata sta rivoluzionando la logistica dei magazzini. Ad esempio, i robot equipaggiati con visione 3D possono prendere oggetti casuali da contenitori per l'imballaggio, riducendo la dipendenza dallo smistamento manuale. Aziende come Amazon e Toyota hanno già integrato tali sistemi nelle loro catene di approvvigionamento. Nella produzione automobilistica, i robot con capacità di presa non ordinata possono gestire i componenti direttamente dal deposito in massa, ottimizzando le linee di produzione e aumentando la flessibilità.
Frontiere della Ricerca :
Gestione Multi-Oggetti : Sviluppare strategie per afferrare più oggetti contemporaneamente o riordinare il disordine per accedere agli oggetti nascosti. Questo potrebbe coinvolgere algoritmi avanzati di pianificazione del movimento che considerano le interazioni tra più oggetti durante la presa e la manipolazione.
Collaborazione Uomo-Robot : Garantire che i robot possano navigare e afferrare oggetti in spazi condivisi, adattandosi ai movimenti umani e agli ostacoli imprevedibili. Ciò richiede sistemi di percezione sofisticati in grado di distinguere tra esseri umani e oggetti, nonché algoritmi di pianificazione del movimento in tempo reale che prioritizzino la sicurezza.
Conclusione
L'afferramento non ordinato nella visione 3D è una rivoluzionaria innovazione per la robotica autonoma, permettendo alle macchine di interagire con il mondo disordinato e non strutturato come fanno gli esseri umani. Integrando percezione avanzata, pianificazione intelligente ed esecuzione adattiva, questa tecnologia aumenta l'efficienza nelle industrie e apre nuove possibilità per robot di servizio più versatili. Con la diminuzione del costo dei sensori 3D e il miglioramento dei modelli di machine learning, l'afferramento non ordinato sbloccherà nuove opportunità nell'automazione, rendendo i robot più capaci, affidabili e pronti per il mondo reale. La ricerca e lo sviluppo in corso in questo campo promettono di ridisegnare il futuro della robotica, dall'automazione industriale all'assistenza quotidiana, abilitando i robot a gestire le complessità degli ambienti non strutturati con facilità.





