

Co to jest nieuporządkowane chwytanie w 3D widzeniu?
W dziedzinie robotyki i wizji komputerowej, nieuporządkowane chwytanie odnosi się do zdolności systemu robota do identyfikacji i chwytania obiektów z nieuporządkowanych, zatłoczonych środowisk bez wiedzy o ich ułożeniu lub pozie. W przeciwieństwie do "uporządkowanego chwytania", gdzie obiekty są równo ustawione lub prezentowane w przewidywalnych orientacjach (np. na taśmie konwejera), nieuporządkowane chwytanie dotyczy chaosu sytuacji z życia codziennego - takich jak stosy przedmiotów w koszu, rozrzucone rzeczy na biurku lub losowo ułożone produkty w magazynie. Ta technologia jest kluczowa dla zastosowań takich jak automatyczne wybieranie z koszy, sortowanie w logistyce i adaptacyjna manipulacja robotem. W miarę jak przemysły dążą do większej automatyzacji, a roboty przechodzą poza kontrolowane środowiska, nieuporządkowane chwytanie stało się podstawą osiągnięcia naprawdę autonomicznych operacji roboczych.
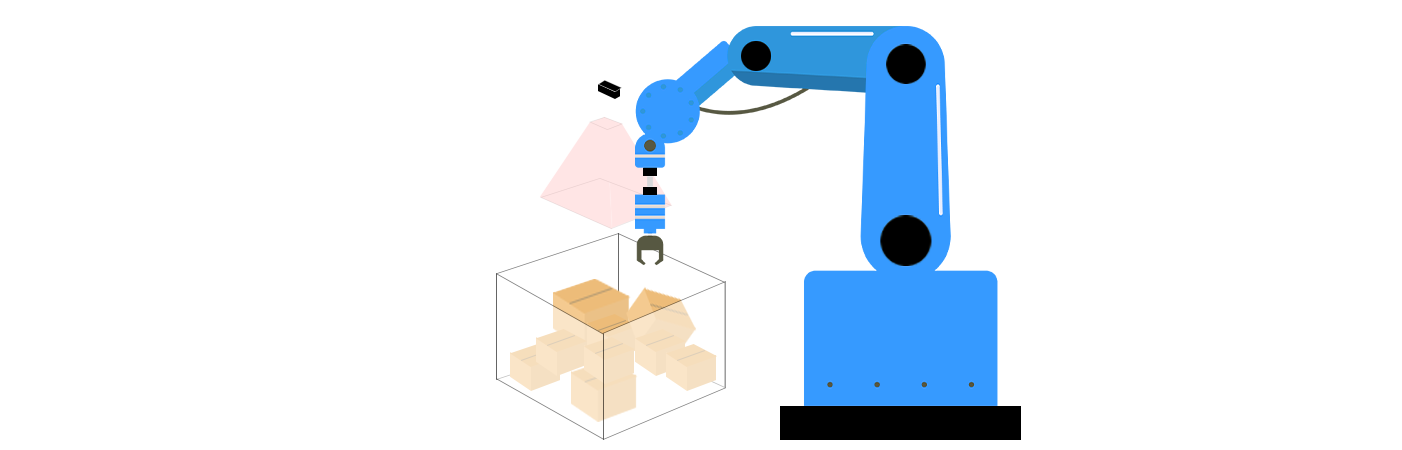
Podstawowe składniki nieuporządkowanego chwytania w 3D widzeniu
Nieuporządkowane chwytanie łączy technologie widzenia w 3D i algorytmy robotyki żeby rozwiązać trzy kluczowe wyzwania: percepcję, planowanie chwytu i wykonanie. Te komponenty działają w tandemie, aby umożliwić robotom zrozumienie otoczenia, ustalenie najlepszego sposobu interakcji z obiektami oraz wykonanie działań z precyzją.
1. percepcja 3D i Zrozumienie Sceny
Wykrywanie Głębokości : układy widzenia 3D używają czujników, takich jak LiDAR, kamery strukturalnego światła lub kamery stereoskopowe, aby przechwytywać informacje o głębokości, tworząc chmury punktów lub modele 3D zatłoczonej sceny. Na przykład LiDAR emituje promienie laserowe, które odbijają się od obiektów i wracają do czujnika, obliczając odległości na podstawie zasady czasu lotu. Kamery strukturalnego światła projekcjonują wzory na obiekty i analizują, jak te wzory się deformują, aby wywnioskować głębokość, podczas gdy kamery stereoskopowe naśladują ludzkie widzenie dwuboczne poprzez użycie dwóch soczewek do triangulacji odległości.
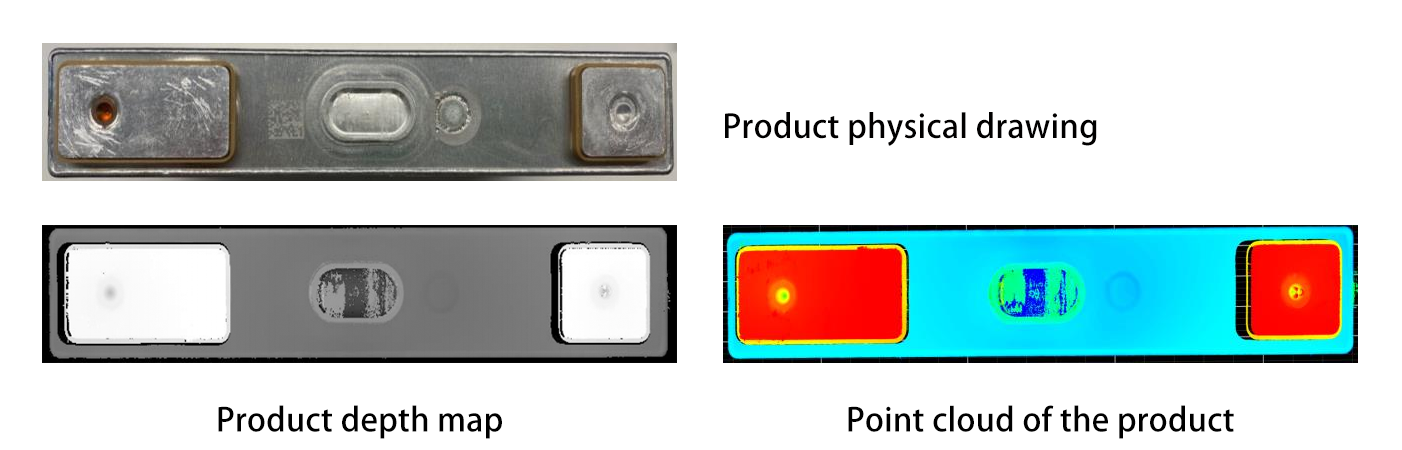
Segmentacja i Rozpoznawanie Obiektów : Zaawansowane algorytmy (np. modele uczenia głębokiego, takie jak PointNet lub Mask R-CNN) przetwarzają dane 3D, aby rozdzielić pojedyncze obiekty od bałaganu i zidentyfikować je. PointNet, pionier w dziedzinie uczenia głębokiego 3D, bezpośrednio przetwarza dane chmury punktów bez konwertowania ich na regularną siatkę, co umożliwia mu zrozumienie geometrycznych cech obiektów w ich naturalnym formacie. Mask R-CNN, z drugiej strony, rozwija popularny framework Faster R-CNN do obsługi segmentacji instancji w 3D, pozwalając robotom na odróżnianie i izolowanie określonych obiektów z złożonych scen. Na przykład, robot może odróżnić część metalową od elementu plastikowego w pomieszanym koszu, analizując ich cechy geometryczne lub tekstury powierzchni. Ponadto techniki, takie jak segmentacja semantyczna, mogą oznaczać różne części obiektu, co jest przydatne do identyfikacji obszarów nadających się do chwytania.
2. Planowanie chwytania w przestrzeni 3D
Po zidentyfikowaniu obiektów, robot musi ustalić, gdzie i jak ma ich chwycić:
Generowanie kandydatów na chwyt : Algorytmy generują potencjalne pozycje chwytu na podstawie kształtu, rozmiaru i właściwości fizycznych obiektu. Metody geometryczne mogą analizować wypukłą powłokę obiektu w celu znalezienia stabilnych punktów kontaktowych, podczas gdy symulacje oparte na fizyce mogą przewidywać, jak szczypce będą oddziaływać z obiektem podczas chwytania. W przypadku walcowatego butelki system może sugerować chwytanie jej w środkowej części za pomocą szczypiec równoległych; w przypadku płaskiej talerza może zaproponować chwyt krawędziowy. Ostatnio sieci neuronowe GAN (Generative Adversarial Networks) zostały wykorzystane do generowania różnorodnych i realistycznych kandydatów na chwyt, ucząc się na dużych zestawach danych udanych chwytów.
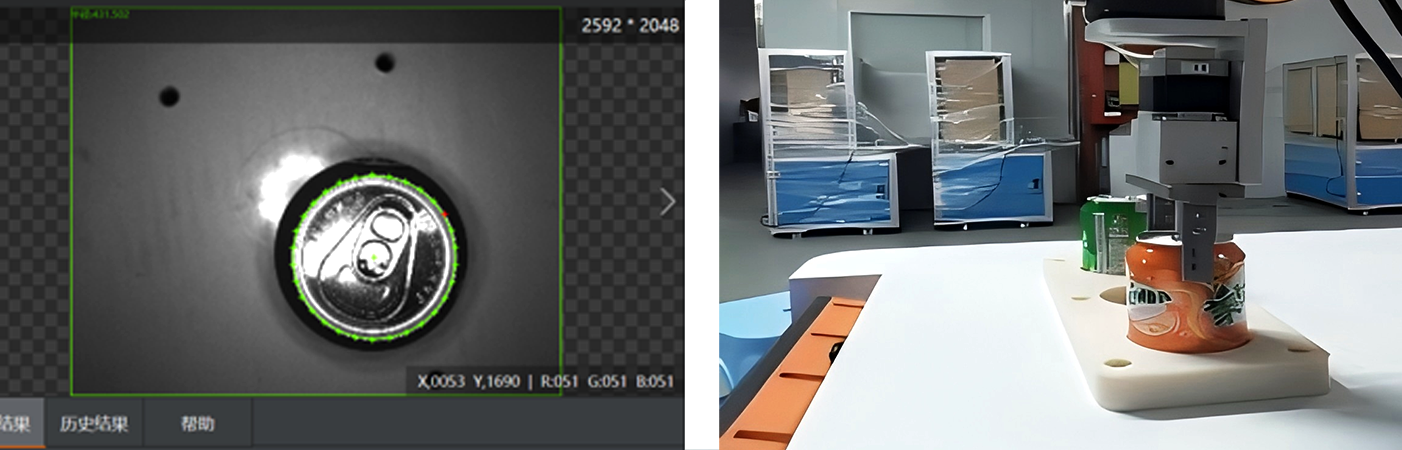
Ocena jakości chwytu : Każda kandydująca do ujęcia pozycja jest oceniana pod względem stabilności (np. czy obiekt się poślizgnie), wykonalności (np. czy chwytak robota może osiągnąć daną pozycję bez kolizji z innymi obiektami) oraz bezpieczeństwa (np. unikanie kruchych obszarów). Modele uczenia maszynowego, wytresowane na tysiącach przykładach 3D obiektów, mogą przewidywać, które ujęcia mają największe prawdopodobieństwo powodzenia. Uczenie wzmacnianie również dało doskonałe wyniki w tej dziedzinie, ponieważ roboty mogą uczyć się optymalnych strategii ujęcia poprzez próby i błędy w środowiskach symulacyjnych.
3. Wykonanie Roboticzne i opinia zwrotna
Robot używa swojego chwytaka lub końcowego wykonawcy, aby wykonać zaplanowane chwycenie, kierowany precyzyjnym oszacowaniem 3D pozy, aby dopasować się do lokalizacji obiektu. Różne typy chwytaków, takie jak chwytaki szczelnikowe, ssawki czy ręce wielopalcowe, wybierane są na podstawie cech obiektu. Na przykład ssawki są idealne dla płaskich, nieporowatych powierzchni, podczas gdy ręce wielopalcowe mogą obsługiwać obiekty o nieregularnym kształcie z większą zręcznością.
Informacje zwrotne w czasie rzeczywistym : Czujniki (np. czujniki siły-obrotu lub kamery wizyjne) dostarczają natychmiastowej informacji zwrotnej podczas chwycenia. Jeśli obiekt przesunie się lub chwytak się przesunie, robot może dostosować swój uścisk lub spróbować ponownie, co poprawia niezawodność w nieuporządkowanych środowiskach. Niektóre zaawansowane systemy nawet używają czujników taktycznych wbudowanych w chwytak, aby wyczuć teksturę i twardość obiektu, co umożliwia bardziej adaptacyjne strategie chwycenia. Na przykład, jeśli czujnik wykryje delikatny obiekt, robot może zmniejszyć siłę uścisku, aby uniknąć uszkodzeń.
Wyzwania związane z nieuporządkowanym chwyceniem
Nierozmyślny chwyt w 3D wizji napotyka na znaczne techniczne przeszkody:
Zakrywanie i Bałagan : Gdy obiekty nachodzą na siebie, trudno jest je odszczepić lub odtworzyć ich pełną kształtę. Na przykład, robot może mieć problem z rozróżnieniem łyżki ukrytej pod stosem widelców. Zaawansowane techniki, takie jak renderowanie objętościowe lub grupowanie grafowe, pomagają rozwiązać te niejednoznaczności. Renderowanie objętościowe może utworzyć model 3D całej sceny, pozwalając algorytmowi na analizę zajmowanej przestrzeni przez obiekty i identyfikację ukrytych przedmiotów. Grupowanie grafowe traktuje każdy obiekt lub chmurę punktów jako węzeł w grafie i wykorzystuje relacje między węzłami, aby oddzielić nachodzące na siebie obiekty. Niemniej jednak, te metody nadal napotykają na problemy przy radzeniu sobie z bardzo złożonym i gęsto spakowanym bałaganem.
Różnorodność Właściwości Obiektów : Przedmioty o złożonych kształtach (np. puste naczynia), elastycznych materiałach (np. tkaniny) lub odbijających powierzchniach (np. szkło) są trudne do dokładnego postrzegania. Fuzja wielu czujników (kombinowanie danych RGB, głębokości i dotyku) oraz wzmacnianie danych (szkolenie modeli na zsymulowanych wariantach) rozwiązuje te problemy. Na przykład, łączenie danych głębokości z czujnikami podczerwieni może pomóc lepiej zrozumieć kształt przedmiotów przezroczystych, podczas gdy wzmacnianie danych może zaprezentować modele uczenia maszynowego szerokiemu zakresowi wyglądu obiektów, poprawiając ich zdolność do uogólniania.
Wykonanie w czasie rzeczywistym : Przetwarzanie wysokiej rozdzielczości danych 3D i generowanie planów chwytu wystarczająco szybko dla odpowiedzi robota wymaga efektywnych algorytmów i przyspieszenia sprzętowego (np. GPU lub jednostki obliczeń brzegowych). Jednakże, osiągnięcie wydajności czasu rzeczywistego przy jednoczesnym utrzymaniu wysokiej dokładności w złożonych środowiskach jest wciąż istotnym wyzwaniem, zwłaszcza przy pracy z dużymi chmurami punktów lub wysokorozdzielczymi modelami 3D.

Zastosowania i przyszłe trendy
Automatyzacja przemysłowa : Nieuporządkowane chwytanie rewolucjonizuje logistykę magazynową. Na przykład, roboty wyposażone w widzenie 3D mogą wybierać losowe przedmioty z koszy na pakowanie, co redukuje zależność od sortowania ręcznego. Firmy takie jak Amazon i Toyota już zintegrowały takie systemy w swoich łańcuchach dostaw. W produkcji samochodowej, roboty z możliwościami nieuporządkowanego chwytania mogą obsługiwać części bezpośrednio z magazynów masowych, optymalizując linie produkcyjne i zwiększając elastyczność.
Fronty Badawcze :
Obsługa Wielu Obiektów : Rozwijanie strategii do chwytania wielu obiektów jednocześnie lub przenoszenia bałaganu, aby uzyskać dostęp do ukrytych przedmiotów. Mogło to obejmować zaawansowane algorytmy planowania ruchu, które uwzględniają interakcje między wieloma obiektami podczas chwytania i manipulacji.
Kolaboracja Człowiek-Robot : Zapewnienie, aby roboty mogły bezpiecznie poruszać się i chwytać obiekty w przestrzeniach udzielonych, dostosowując się do ruchów człowieka i nieprzewidywalnych przeszkód. Wymaga to zaawansowanych systemów percepcji, które potrafią rozróżniać między ludźmi a obiektami, oraz algorytmów planowania ruchu w czasie rzeczywistym, które mają priorytet bezpieczeństwa.
Podsumowanie
Nieroz sezony w 3D wizji jest kluczowym przełomem dla robotyki autonomicznej, umożliwiając maszynom interakcję z nieuporządkowanym światem tak, jak to robią ludzie. Dzięki integracji zaawansowanego wyczuwania, inteligentnego planowania i adaptacyjnego wykonywania, ta technologia zwiększa efektywność w przemyśle i otwiera drzwi na bardziej uniwersalne roboty usługowe. W miarę gdy czujniki 3D stają się taniejsze, a modele uczenia maszynowego bardziej odporne, nieroz sezon odblokują nowe możliwości w automatyce, czyniąc roboty bardziej zdolnymi, niezawodnymi i gotowymi do działania w rzeczywistym świecie. Trwałe badania i rozwój w tej dziedzinie obiecują przekształcić przyszłość robotyki, od automatyzacji przemysłowej po codzienną pomoc, umożliwiac robotom radzenie sobie z złożonościami środowisk nieuporządkowanych bez problemu.





