

Dois Tipos de Algoritmos para Visão Computacional
A visão por computador tornou-se um ponto central na automação industrial, permitindo um controle de qualidade eficiente e a detecção de defeitos. No seu núcleo, a visão por computador depende de algoritmos para replicar o julgamento visual humano. Esses algoritmos podem ser divididos em duas categorias principais: sistemas baseados em regras e algoritmos de aprendizado profundo . Compreender seus princípios, forças e limitações é crucial para otimizar suas aplicações em cenários do mundo real.
Sistemas baseados em regras
Algoritmos baseados em regras: Esses sistemas analisam características específicas de um objeto — como cor, forma ou valores de escala de cinza — e os comparam com limiares ou padrões estabelecidos. Por exemplo:
- Uma folha de papel branca com manchas pode ser marcada como defeituosa porque as manchas apresentam um valor de escala de cinza distinto do fundo.
- Um produto que falta um logotipo padrão (um padrão pré-definido) é considerado (não conforme) por meio de correspondência de modelo.

Vantagens :
Facilidade de Implantação regras são simples de programar uma vez que os padrões de recursos estejam bem definidos.
Baixo custo computacional : Requisitos mínimos de hardware devido a cálculos determinísticos.
Limitações :
Requisitos ambientais rígidos : Iluminação, ângulos de câmera e posicionamento do produto devem permanecer altamente consistentes.
Adaptabilidade limitada : Até mesmo pequenas variações na aparência do produto (por exemplo, flutuações na textura do material) ou defeitos irregulares (por exemplo, arranhões aleatórios) podem levar a julgamentos incorretos.
Na prática, sistemas baseados em regras se destacam em ambientes altamente controlados onde as especificações do produto e as condições de inspeção são estritamente padronizadas. No entanto, sua fragilidade fica evidente em configurações dinâmicas ou imprevisíveis.
Algoritmos de Aprendizado Profundo: Aprendendo com Complexidade
A aprendizado profundo imita os processos cognitivos humanos treinando redes neurais em grandes conjuntos de dados. Ao contrário dos sistemas baseados em regras, esses algoritmos extraem automaticamente características de imagens, permitindo que lidem com cenários complexos como:
Detectando defeitos irregulares (por exemplo, rachaduras ou manchas de forma aleatória).
Diferenciação de objetos em fundos bagunçados.

Vantagens :
Alta precisão em ambientes caóticos : Adapta-se a variações de iluminação, ângulos e inconsistências de produto.
Generalizabilidade : Uma vez treinados, os modelos podem reconhecer padrões de defeito novos dentro das categorias aprendidas.
Desafios :
Fome de dados : O treinamento requer centenas a milhares de imagens rotuladas, com forte dependência de amostras defeituosas. Na manufatura, defeitos são frequentemente raros, necessitando de fases prolongadas de coleta de dados (semanas a meses).
Problemas de escalabilidade : Mudar para uma nova especificação de produto geralmente exige retreinamento do zero, aumentando os custos de tempo e recursos.
Escolher a Ferramenta Certa: O Contexto Importa
A escolha entre algoritmos baseados em regras e aprendizado profundo depende de casos de uso específicos:
Sistemas baseados em regras se destacam na produção em alto volume e padronizada (por exemplo, componentes de semicondutores) onde a consistência é garantida.
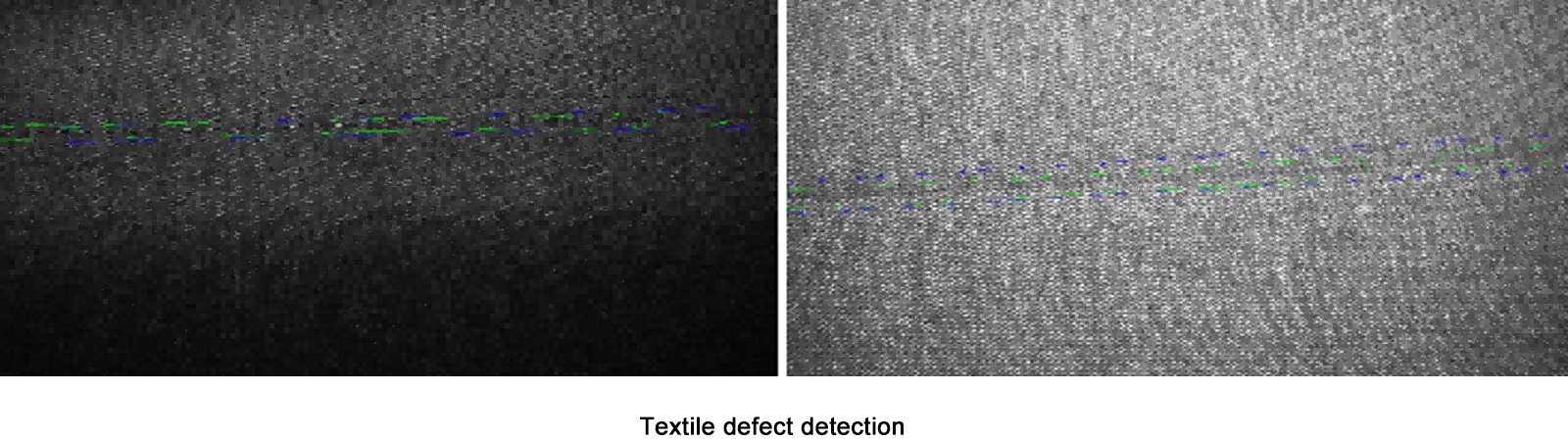
Aprendizado profundo se destaca em cenários de baixo volume e alta variabilidade (por exemplo, detecção de defeitos em tecidos) ou quando os defeitos não apresentam padrões previsíveis.
Notavelmente, abordagens híbridas estão surgindo. Por exemplo, filtros baseados em regras podem pré-processar imagens para reduzir as cargas de trabalho de aprendizado profundo, enquanto ferramentas de geração de dados sintéticos aliviam a escassez de amostras de treinamento.
Conclusão
A eficácia da visão computacional depende de alinhar as capacidades algorítmicas com as realidades operacionais. Sistemas baseados em regras oferecem simplicidade e velocidade, mas fracassam em ambientes imprevisíveis. Aprendizado profundo proporciona flexibilidade e precisão, mas exige um investimento significativo inicial. No final, a estabilidade de qualquer sistema depende de três fatores: uniformidade do produto, controle ambiental e diversidade de amostras. Dominar essas variáveis garante que a visão computacional cumpra sua promessa de precisão e confiabilidade.





