

What is Unordered Grasping in 3D Vision?
In the field of robotics and computer vision, unordered grasping refers to a robotic system's ability to identify and grasp objects from unstructured, cluttered environments without prior knowledge of their arrangement or pose. Unlike "ordered grasping," where objects are neatly aligned or presented in predictable orientations (e.g., on a conveyor belt), unordered grasping deals with the chaos of real-world scenarios—such as piles of objects in a bin, scattered items on a desk, or randomly stacked products in a warehouse. This technology is vital for applications like automated bin picking, logistics sorting, and adaptive robotic manipulation. As industries strive for greater automation and robots move beyond controlled environments, unordered grasping has emerged as a cornerstone for achieving truly autonomous robotic operations.
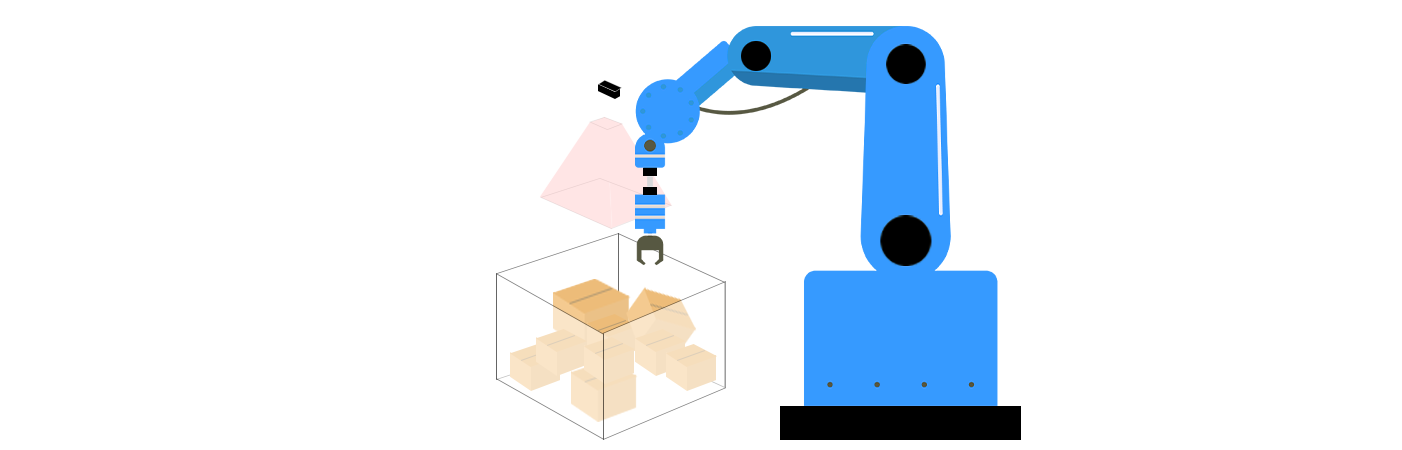
Core Components of Unordered Grasping in 3D Vision
Unordered grasping combines 3D vision technologies and robotics algorithms to solve three key challenges: perception, grasp planning, and execution. These components work in tandem to enable robots to understand their surroundings, determine the best way to interact with objects, and execute actions with precision.
1. 3D Perception and Scene Understanding
Depth Sensing: 3D vision systems use sensors like LiDAR, structured light cameras, or stereo cameras to capture depth information, creating point clouds or 3D models of the cluttered scene. LiDAR, for instance, emits laser beams that bounce off objects and return to the sensor, calculating distances based on the time-of-flight principle. Structured light cameras project patterns onto objects and analyze how these patterns deform to infer depth, while stereo cameras mimic human binocular vision by using two lenses to triangulate distances.
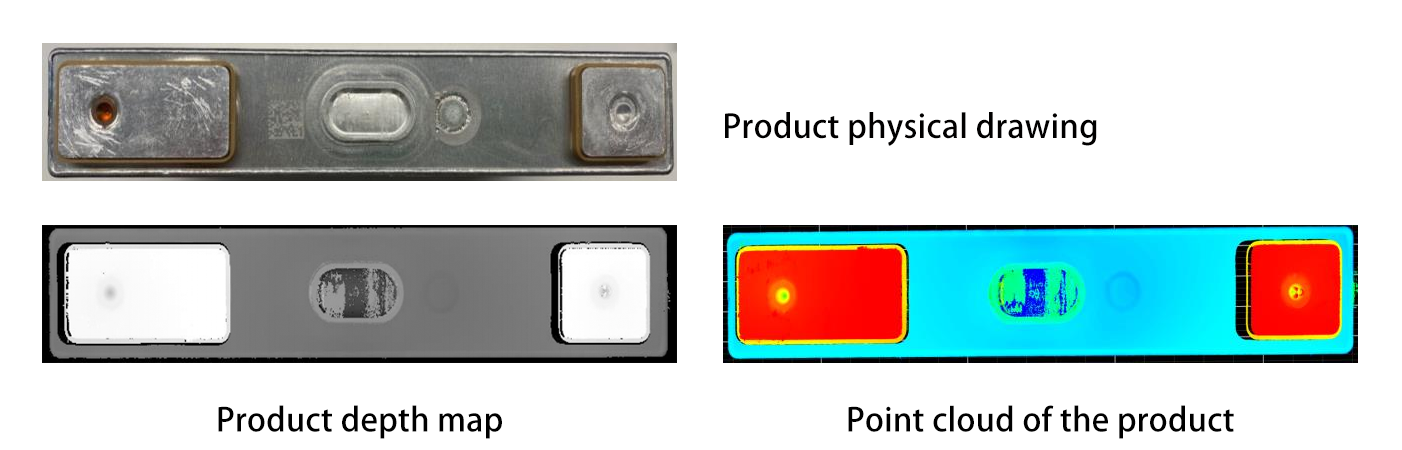
Object Segmentation and Recognition: Advanced algorithms (e.g., deep learning models like PointNet or Mask R-CNN) process 3D data to separate individual objects from the clutter and identify them. PointNet, a pioneer in 3D deep learning, directly processes point cloud data without converting it into a regular grid, enabling it to understand the geometric features of objects in their native format. Mask R-CNN, on the other hand, extends the popular Faster R-CNN framework to handle instance segmentation in 3D, allowing robots to distinguish and isolate specific objects from complex scenes. For example, a robot might distinguish a metal part from a plastic component in a jumbled bin by analyzing their geometric features or surface textures. Additionally, techniques like semantic segmentation can label different parts of an object, which is useful for identifying areas suitable for grasping.
2. Grasp Planning in 3D Space
Once objects are identified, the robot must determine where and how to grasp them:
Grasp Candidate Generation: Algorithms generate potential grasp poses based on an object’s shape, size, and physical properties. Geometric approaches might analyze the convex hull of an object to find stable contact points, while physics-based simulations can predict how a gripper will interact with the object during a grasp. For a cylindrical bottle, the system might suggest grasping its midsection with parallel jaws; for a flat plate, it might propose a pinch grasp on the edge. More recently, generative adversarial networks (GANs) have been employed to generate diverse and realistic grasp candidates by learning from large datasets of successful grasps.
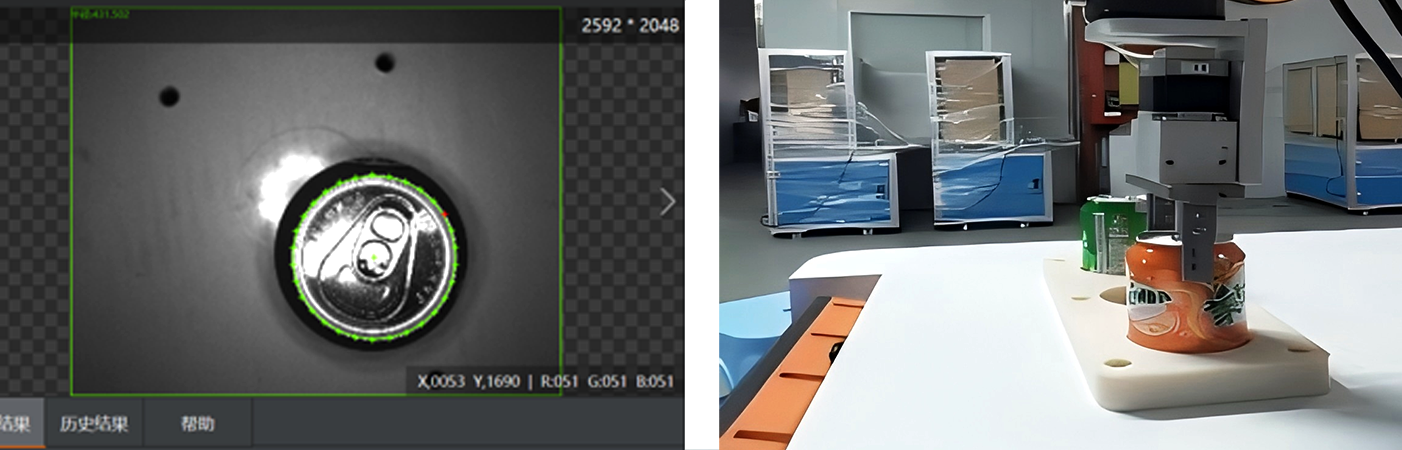
Grasp Quality Evaluation: Each candidate grasp is evaluated for stability (e.g., whether the object will slip), feasibility (e.g., if the robot’s gripper can reach the pose without colliding with other objects), and safety (e.g., avoiding fragile areas). Machine learning models, trained on thousands of 3D object examples, can predict which grasps are most likely to succeed. Reinforcement learning has also shown great promise in this area, as robots can learn optimal grasp strategies through trial and error in simulated environments.
3. Robotic Execution and Feedback
The robot uses its gripper or end-effector to execute the planned grasp, guided by precise 3D pose estimation to align with the object’s location. Different types of grippers, such as parallel-jaw grippers, suction cups, or multi-fingered hands, are selected based on the object's characteristics. For example, suction cups are ideal for flat, non-porous surfaces, while multi-fingered hands can handle irregularly shaped objects with greater dexterity.
Real-Time Feedback: Sensors (e.g., force-torque sensors or vision cameras) provide instant feedback during the grasp. If the object shifts or the gripper slips, the robot can adjust its grip or retry the grasp, improving reliability in messy environments. Some advanced systems even use tactile sensors embedded in the gripper to sense the object's texture and hardness, allowing for more adaptive grasping strategies. For instance, if the sensor detects a delicate object, the robot can reduce the gripping force to avoid damage.
Challenges in Unordered Grasping
Unordered grasping in 3D vision faces significant technical hurdles:
Occlusion and Clutter: When objects overlap, it is difficult to segment them or reconstruct their full shape. For example, a robot might struggle to distinguish a spoon buried under a pile of forks. Advanced techniques like volumetric rendering or graph-based clustering help resolve these ambiguities. Volumetric rendering can create a 3D model of the entire scene, allowing the algorithm to analyze the spatial occupancy of objects and identify hidden items. Graph-based clustering treats each object or point cloud as a node in a graph and uses relationships between nodes to separate overlapping objects. However, these methods still face challenges when dealing with highly complex and densely packed clutter.
Diverse Object Properties: Objects with complex shapes (e.g., hollow containers), flexible materials (e.g., fabric), or reflective surfaces (e.g., glass) are hard to perceive accurately. Multi-sensor fusion (combining RGB, depth, and tactile data) and data augmentation (training models on simulated variations) address these issues. For example, combining depth data with infrared sensors can help in better understanding the shape of transparent objects, while data augmentation can expose machine learning models to a wide variety of object appearances, improving their generalization ability.
Real-Time Performance: Processing high-resolution 3D data and generating grasp plans quickly enough for robotic response requires efficient algorithms and hardware acceleration (e.g., GPUs or edge computing units). However, achieving real-time performance while maintaining high accuracy in complex environments is still a significant challenge, especially when dealing with large point clouds or high-definition 3D models.

Applications and Future Trends
Industrial Automation: Unordered grasping is revolutionizing warehouse logistics. For example, robots equipped with 3D vision can pick random items from bins for packaging, reducing reliance on manual sorting. Companies like Amazon and Toyota have already integrated such systems into their supply chains. In automotive manufacturing, robots with unordered grasping capabilities can handle parts directly from bulk storage, streamlining production lines and increasing flexibility.
Research Frontiers:
Multi-Object Handling: Developing strategies to grasp multiple objects at once or reposition clutter to access hidden items. This could involve advanced motion planning algorithms that consider the interactions between multiple objects during grasping and manipulation.
Human-Robot Collaboration: Ensuring robots can safely navigate and grasp objects in shared spaces, adapting to human movements and unpredictable obstacles. This requires sophisticated perception systems that can distinguish between humans and objects, as well as real-time motion planning algorithms that prioritize safety.
Conclusion
Unordered grasping in 3D vision is a critical breakthrough for autonomous robotics, enabling machines to interact with the messy, unstructured world as humans do. By integrating advanced perception, intelligent planning, and adaptive execution, this technology drives efficiency in industries and opens doors to more versatile service robots. As 3D sensors become cheaper and machine learning models more robust, unordered grasping will unlock new possibilities in automation, making robots more capable, reliable, and ready for the real world. The ongoing research and development in this field promise to reshape the future of robotics, from industrial automation to everyday assistance, by empowering robots to handle the complexities of unstructured environments with ease.





